Vulkan 导读1: 下一代图形API
写在之前:此篇为Danny针对《Learning Vulkan》一书的导读。导读的目的主要是将一些重要的概念重点归纳和解释,并对不清楚的概念提出疑问,作为后续工作和学习中的待澄清点。
Danny认为,一本好的书,是可以加深技术理解,自画自圆,其义自见的;一本不好的书,要靠读者去猜,搜索很多其他补助资料才能澄清。优秀的书是可以从全局观开始,聚焦到细节。一本不好的书,说的都是正确的废话。 最近读了两本关于Vulkan的书,一本是电子版的《Learning Vulkan》。

一本是花了$175购买的纸质的《Computer Graphics and the Vulkan API》
两本书都是对下一代图形API的细节展开,Danny希望通过一种导读的形式来将这两本书的一些重要概念融合一下。写这篇文章的内容不是说大家看导读就不用去读书了,而是希望辅助大家阅读图书。如今的时代都是速食知识消费,time is money。 大家都没有时间,但是这种速食知识消费很容易让大家知其然而不知其所以然。
导读的梳理其实比较耗时间。技术读物不像读小说那样可以进行速读,阅读过程要注意的环节是避免眼球回跳。但是,很多内容还是需要理解和自我提问,甚至对于解释模糊不清的内容还要查阅第三方资料。所以花一个礼拜读完一本技术书,两天后可能只记得几幅图片了。 技术内容的阅读还是要记录笔记和操作代码尝试同步进行,毕竟别人嚼过的饭菜自己吃着肯定没有味道。
小的时候电视节目不多,网络也不发达,那个时候是真的可以安心看看几本书;长大了之后,我们的耐心呢?那我们回到正文吧。
名词解释
Physical device and device:A physical device represents a unique device,whereas a device refers to a logical representation of the physical device in anapplication.
Memory type:两种内存类型,host 和 device。
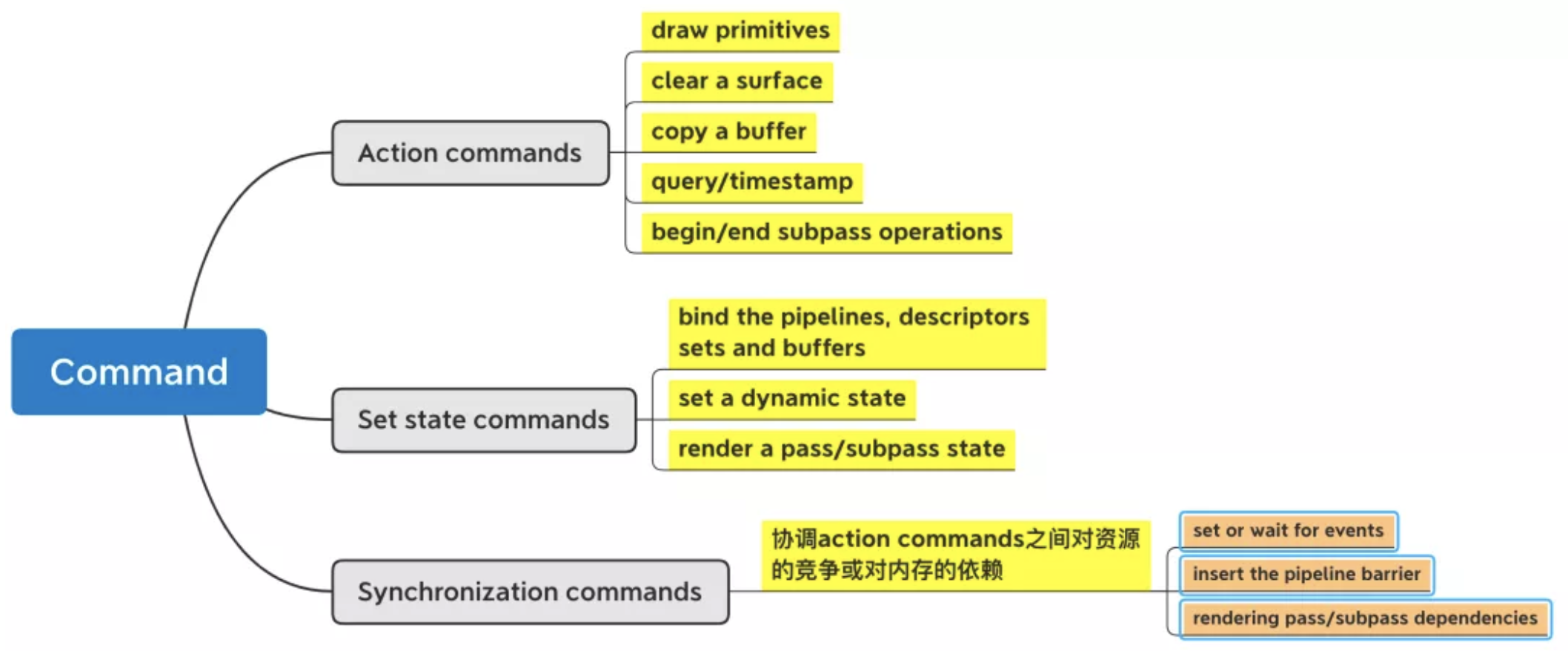
Command: 某个行为的指令。具体包括三种,action,set state,sync。
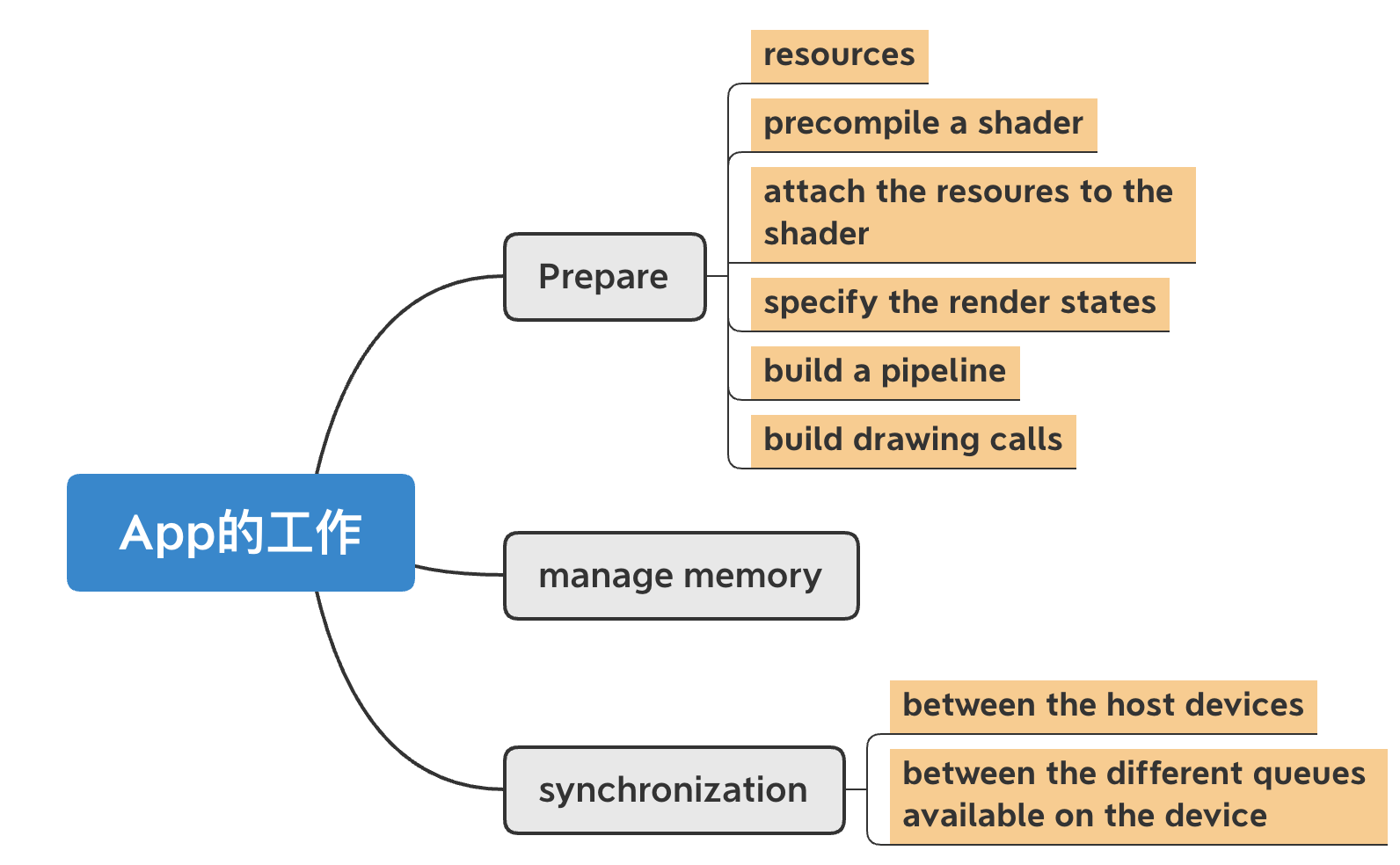
Vulkan的工作机制
- Vulkan 让应用程序显式地管理内存。
- Command buffers 被提交到queues上,然后由queues把这些command buffer jobs提交给物理设备处理。

Vulkan’s Queues
- Queues是把command buffers 喂给GPU设备的媒介。
- Command Buffers 记录一个或多个commands并把它们提交给指定的queue上。
- 设备一般会有多个queues,所以把command buffer提交到queue的工作要由app来负责。
- Command buffers 可以被提交到一个 或 多个Queue上。
Single Queue:
- 维护了command buffer的submission和execution的顺序,和playback。 (playback是什么,这里先带着问号,之后去找解释。)
- Command Buffers 是按照顺序执行的。
多个Queues的时候
- 允许command buffer在两个甚至多个queues上平行执行
- 除非需要显式的定义,command buffers 的提交和执行顺序 不能得到保证。 应用程序必须对同步机制负责。否则,执行的顺序可能完全失控。
Vulkan 的同步机制
Semaphore: 用来同步多个queues或者 a coarse-grained command buffer submission in a single queue
Events: 用来控制fine-grained sychronization 并且用在single queue上,使同步工作既可以在single command buffer上完成 也可以在a sequence of command buffers on a single queue上完成。
Fences: 允许 同步可以在host 和设备两者之间完成。
Pipeline Barriers:a pipeline barrier 是一个被插入的instruction,它用来保证一个command buffer里的被插入的这个instructuction的前边的commands必须比它后边的commands先执行。
Vulkan Objects
从应用层角度出发:所有的entities,包括devices,queues,command buffers, framebuffers, pipelines等都叫做Vulkan Objects。
从API 层来看,这些Vulkan Objects被认为是handles。这些handles分成两种:
Dispatchable handles:这种handle是一个指针,指向一个不可以直接被access或是一个不可以被更改其内部fields的entity。这些fields的只能通过API的方式来access。 每一个dispatchable handle都有一个相关的dispatchable type。handle是可以作为parameter 被传入API的command里。这些handle包括如下:

Non-dispatchable handles:64-bit integer 类型的handles。这种类型的handle并不是指针,相反,它可能会存有它所表示的object的信息。

Objects的生命周期 and command syntax
Vulkan的对象是由app来显式地create和destory的。Vulkan提供了create和destroy两种command来创建和删除object。
这些command 的 syntax如下:
- Create syntax: Objects are created using the vkCreate* command; this accepts a Vk*CreateInfo structure as a parameter input
- Destroy syntax: The objects produced using the Create command are destroyed using vkDestroy*
从现有object pool 或者 heap 上创建的Objects 是通过 Allocate command 创建,释放是通过Free。
Allocate syntax: Objects that are created as part of an object pool use vkAllocate* along with Vk*AllocateInfo as an argument input.
Freeing syntax: Objects are released back to the pool or memory using the vkFree* command.
通常来说,Vulkan的command可以简单的区分为两种,一种是Get型,另一种是record型。
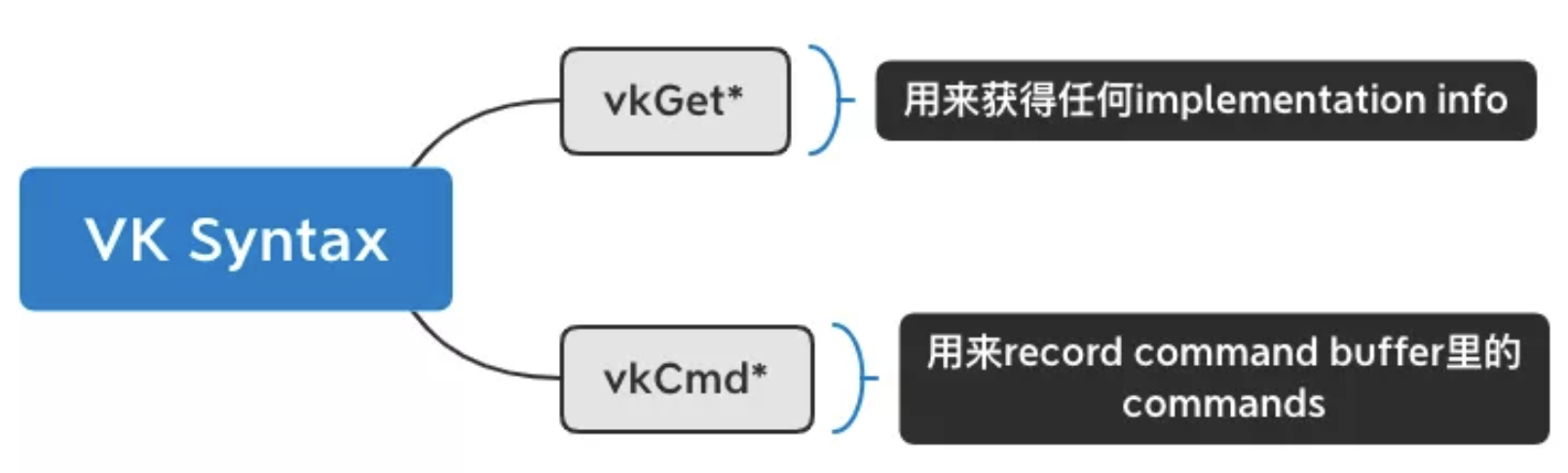
Vulkan 应用跟周边的关系
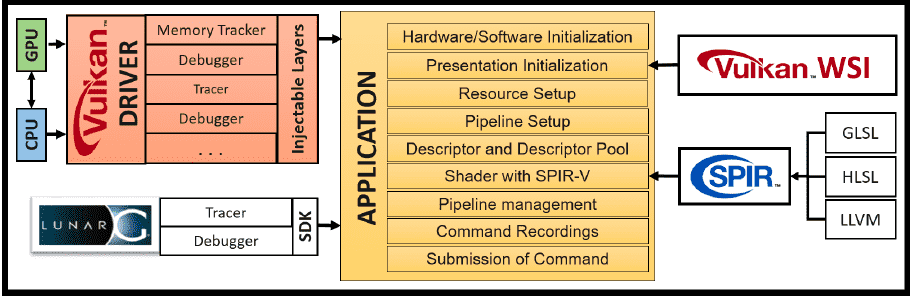
对于上述各个组件,请参考Learning Vulkan英文解释如下:
Driver
A Vulkan-capable system comprises a minimum of one CPU and GPU. IHV’s vendor supplies the driver of a given Vulkan specification implementation for their dedicated GPU architecture. The driver acts as an interface between the application and the device itself. It provides high-level facilities to the application so it can communicate with the device. For example, it advertises the number of devices available on the system, their queues and queue capabilities, available heaps and their related properties, and so on.
Application
An application refers to a user-written program that is intended to make use of Vulkan APIs to perform graphics or compute jobs. The application starts with the initialization of the hardware and software; it detects the driver and loads all the Vulkan APIs. The presentation layer is initialized with Vulkan’s Window System Integration (WSI) APIs; WSI will be helpful in rendering the drawing image on the display surface. The application creates resources and binds them to the shader stage using descriptors. The descriptor set layout helps bind the created resources to the underlying pipeline object that is created (of the graphics or compute type). Finally, command buffers are recorded and submitted to the queue for processing.
WSI
Windows System Integration is a set of extensions from Khronos for the unification of the presentation layer across different platforms, such as Linux, Windows, and Android.
SPIR-V
SPIR-V provides a precompiled binary format for specifying shaders to Vulkan. Compilers are available for various shader source languages, including variants of GLSL and HLSL, which produce SPIR-V.
LunarG SDK
The Vulkan SDK from LunarG comprises a variety of tools and resources to aid Vulkan application development. These tools and resources include the Vulkan loader, validation layers, trace and replay tools, SPIR-V tools, Vulkan runtime installer, documentation, samples, and demos…You can read more about it at http://lunarg.com/vulkan-sdk.
Vulkan开发流程
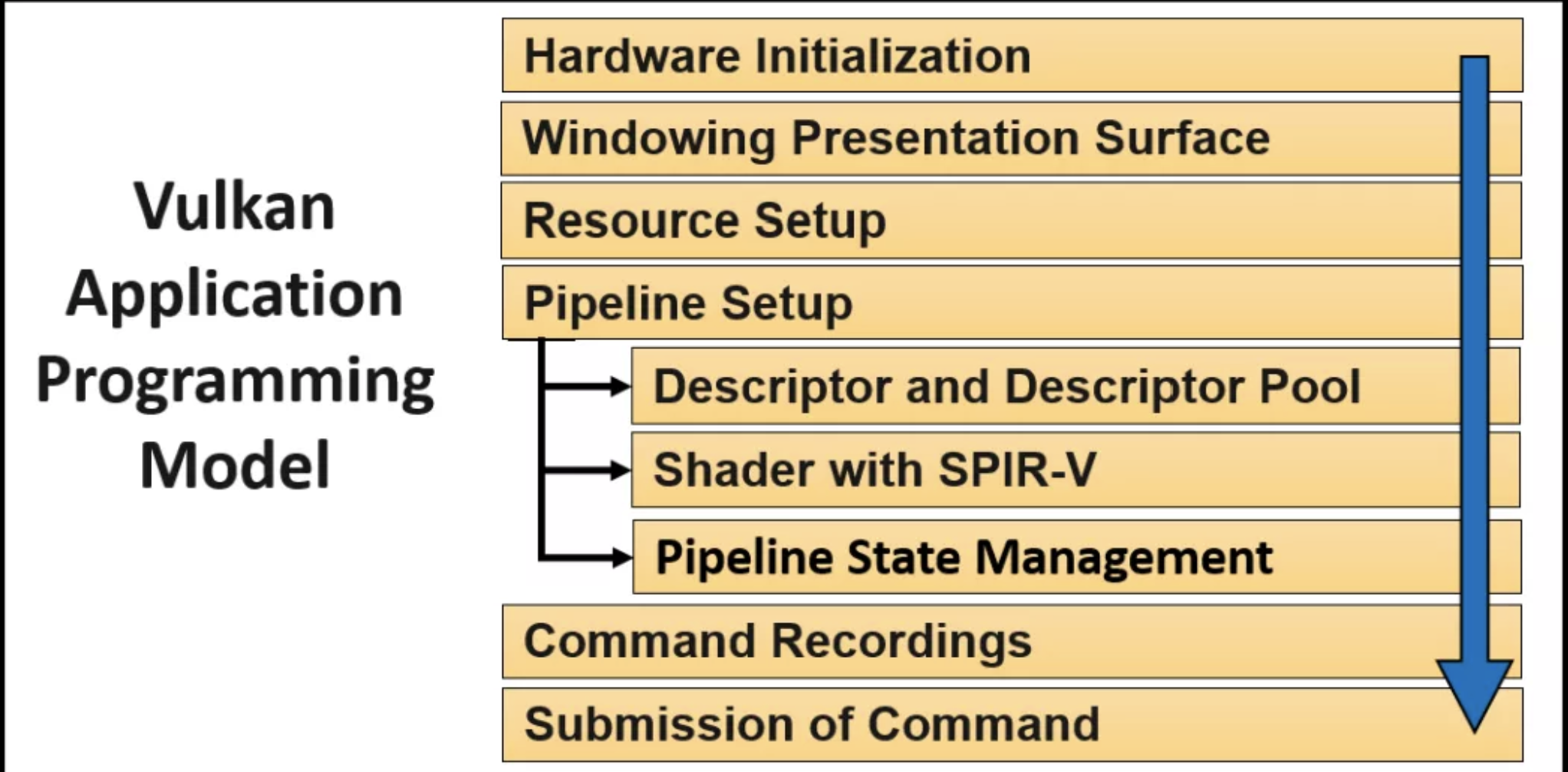
1. 硬件初始化
Application通过Loader来激活Vulkan 的drivers。Loader包含以下组件:
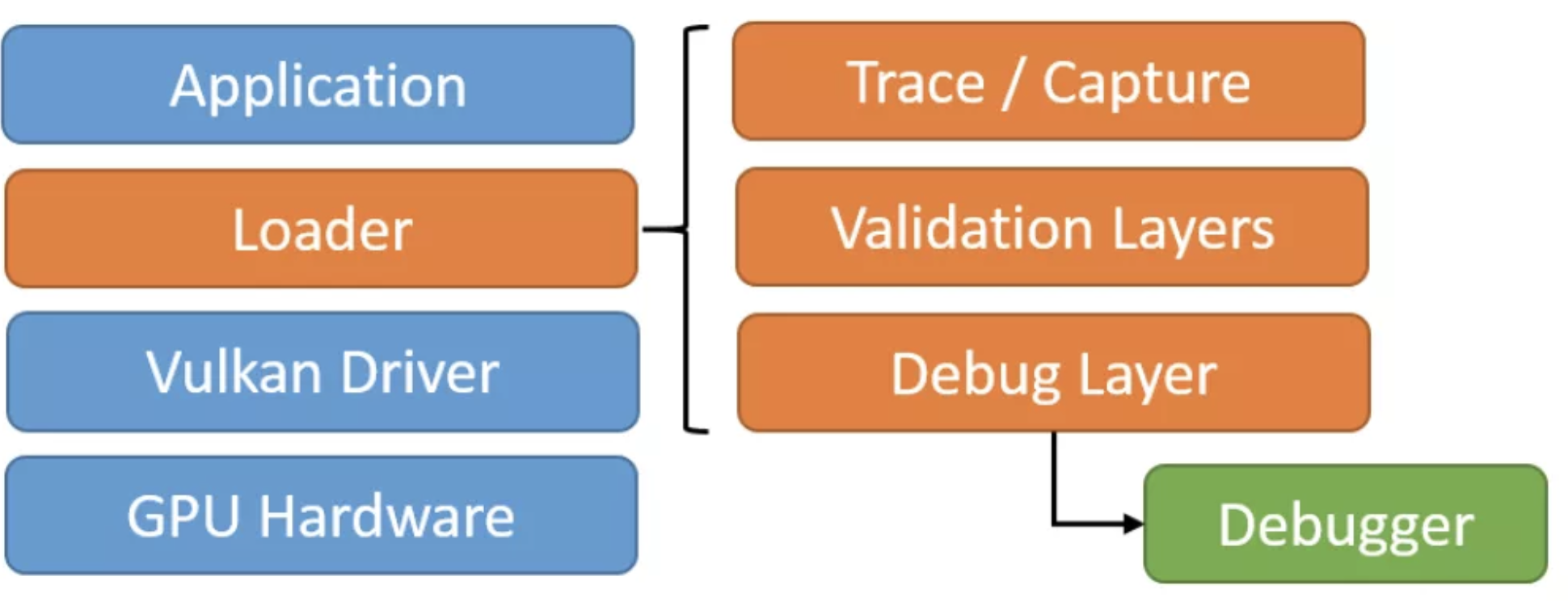
名词解释:Loader。是一组代码。因为Vulkan是跨平台的,所以在应用程序启动的时候来,loader是用来定位应用程序所处系统的Vulkan的driver。
Loader有三个主要的职责:
Locating drivers, Platform-independent, 和 Injectale layers
当loader完成了drivers的定位和其API 的linking后,App就要负责完成以下操作:
创建Vulkan Instance
查询可用的GPU物理设备所能提供的queues
查询extensions,并把extensions存储为function pointers, 例如WSI 或者 speicial feature APIs
使能一个injectable layer来做error checking,debugging 或者 validation
2. 窗口展现
当完成了loader定位driver这一环节,我们就可以用Vulkan API来draw东西了。这里,我们需要一个image来执行drawing task,并把image放的presetation window去显示出来。
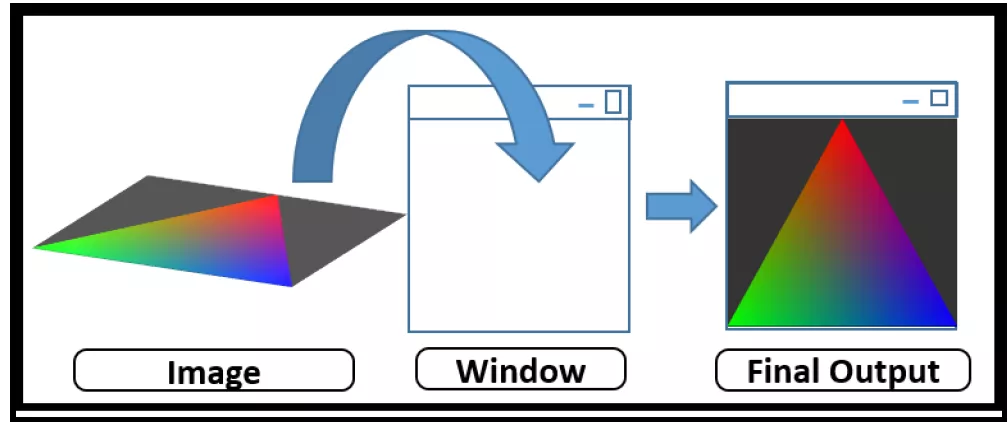
跟OpenGL不同的是,Vulkan的context 和 device没有包括window system,Vulkan是通过Windows System Integration(WSI)来管理的 window的,而GL的context和device是在创建windows system framebuffer时就一起创建好了。
WSI 包括了一组跨平台的窗口管理拓展。可以支撑Windows,Linux,Android等不同的操作系统。并且它是一套consistent API标准,可以简单地用来创建surfaces,并把sufaces显示出来。
WSI提供了swapchain的机制。这个机制允许使用多个images,这就使得当窗口系统在显示一个image的时候,App可以准备下一个image。下图解释了double-buffering swap image的过程。这个过程使用了两个images。在WSI的协助下,这个两个images在App和Display两者间被交换使用。
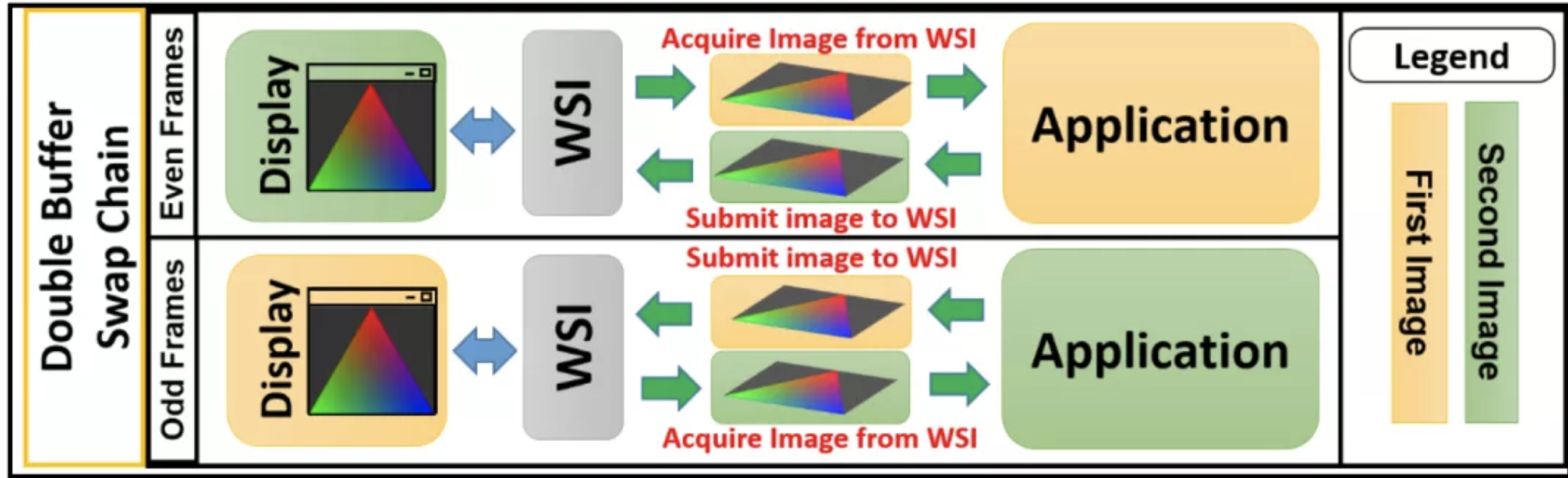
WSI 是Display和应用中间的interface。它能够保证Display和Application在使用两个images的过程中是互不干扰的。当App在第一个Image上工作的时候,WSI把第二个Image 交给Display来渲染其内容到屏幕上。当App完成了对第一个image的绘图,App就把第一个image提交给WSI,然后获取第二个image来继续一下个draw的工作。
这里可以理解为image相当于OpenGL里的FrameBuffer, 即内存中的一块区域,它存储了GPU通过它的pipeline流程后最终显示在屏幕上的结果。image的内容,即将要在显示在屏幕上的内容。
所以此刻,我们将完成下面的操作:
- Create a native window (like the CreateWindow method in the Windows OS)
- Create a WSI surface attached to the window
- Create the swapchain to present to the surface
- Request the drawing images from the created swapchain
3. 资源配置
配置资源意味着存储数据到内存的指定区域。这些数据可能是任何类型的。例如,vertex attributes,包括position,color,image type/name.
不同于OpenGL那种隐性的管理内存的方式(这里说到隐性的意思是OpenGL本身自己来管理内存,不需要过多的要求用户来管理内存),Vulkan提供了full low-level access and control of memory。Vulkan会广告出物理设备上各式各样的可用的内存,来让App对其做显式的管理。
Memory Heap 按照其performance可以分为两类:
Host Local:CPU使用的内存,但是对于GPU读取来说是slower typer of memory
Device Local:直接attached到GPU物理设备的内存,对于GPU来说是high bandwidth,faster
按照,内存的配置,又可以分成三种:
| Device Local | Device Local and host visible | Host Local and host visible | |
|---|---|---|---|
| Visible to device | Yes | Yes | Yes |
| Visible to host | No | Yes | Yes |
Vulkan 是让App来显式的管理内存资源的。以下是内存管理的process:
Resource Objects:App 来allocate内存资源,这些内存资源包括images或者buffer ojbects
Allocation and suballocaiton: 这一段节选书中原文的解释,是内存管理和工作机制的最重要一段内容。
“When resource objects are created, only logical addresses are associated with them; there is no physical backing available. The application **allocates physical memory and binds these logical addresses to it. As allocation is an expensive process, suballocation is an efficient way to manage the memory; it allocates a big chunk of physical memory at once and puts different resource objects into it. Suballocation is the responsibility of an application. The following diagram shows the suballocated object from the big allocated piece of physical memory:”

Sparse memory: 对于超大的image objects,Vulkan自持Sparse memory。Danny对sparse memory的理解就是原来本可以一整块的memory中的对象,但是由于此对象太大,已经超出了内存本身的capacity,Vulkan就把这个超大image object 拆解成tiles,然后只load那些App逻辑处理时需要的tiles。
Staging Buffers:object buffer 和 image buffer 的数据填充是在staging 这个环节完成的。在这个环节里,两个不同的内存区域被用来做物理分配。 对于一个资源的理想的内存放置区域可能是一块host不可见的内存,那么在这种情况下,App就需要先在host-visible的staging buffer这个阶段把resource的数据或者字段填充好,然后再把这个resource转到理想的device local的的内存区域里。
Asynchronous Transfer: 数据的传输是通过DMA、Transfer queues的异步commands 来完成的。
此处书中提到关于OpenGL针对内存的管理,原文值得阅读:
“In contrast, OpenGL resource management does not offer granular control over the memory. There is no conception of host and device memory;\ the driver secretly does all of the allocation in the background. Also, these allocation and suballocation processes are not fully transparent and might change from one driver to another. This lack of consistency and hidden memory management cause unpredictable behavior. Vulkan, on the other hand, allocates the object right there in the chosen memory, making it highly predictable.”
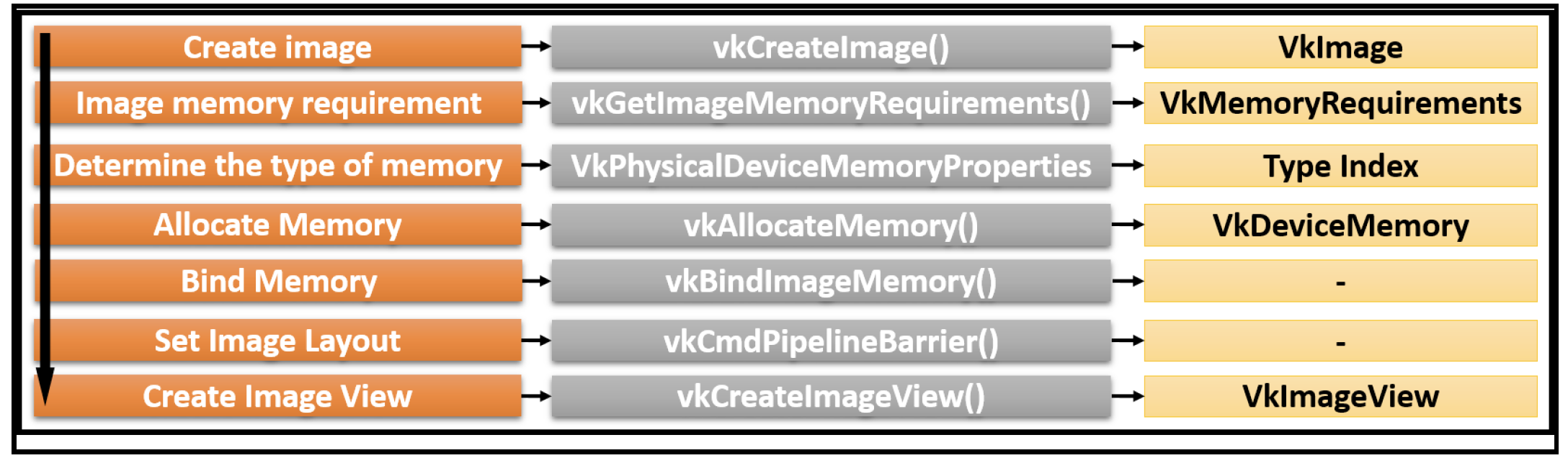
所以,资源配置有以下5步:
- 创建a resource object
- 查询合适的内存instance and create内存对象,例如buffer 和 images
- Get 内存allocation的requirements
- Allocate space 并把数据存储进去
- 绑定resource object到内存
思考:这5步书中没有解释清楚,感觉是第4步先把数据写入内存,再绑定对象到内存中。这种做法非常像OpenGL的VBO 和VAO的概念。即先把绘图模型的数据写入VBO 的buffer里,然后再通过绑定context 当前的VAO来描述VBO里的数据的属性。 建议这块内容在后期Vulkan 的 resource object 创建时看看具体的操作对比OpenGL是怎么进行的。
4. 管线配置
一条pipeline其实就是一组events。这些events会按照application的logic依次发生。这些events包括:供应shaders,把shaders绑定到resource上,并管理其pipeline的state。

既然管线分成上述三部分,那么就需要对这三部分进行配置。
Descriptor sets and descriptor pools
名词解释
A descriptor set 就是resources 和 shaders 之间的interface。 它是一个简单的结构体,可以把shader绑定到resource 上,例如 images或者buffers。它跟shader将要用的一块resouce memory相关联或者bind。 以下是跟descriptor sets相关的一些特点:
- Frequent change: By nature, a descriptor set changes frequently; generally, it contains attributes such as material, texture, and so on.
- Descriptor pool: Considering the nature of descriptor sets, they are allocated from a descriptor pool without introducing global synchronization.
- Multithread scalability: his allows multiple threads to update the descriptor set simultaneously
所以a descrptor set的fields会经常被改变;他们是由descriptor 池allocate 出来的;一个descriptor set结构体可以同时被多个threads更新。
注意:更新或者修改一个descriptor set结构体是Vulkan中性能最关键的路径。所以,descriptor的结构设计是实现最大性能的一个重要部分。Vulkan 支持三种不同的程度的针对多个descriptor set结构体的logical partitioning。这三种分别是:在scene(low frequency updates),model(medium frequence udpates),和 draw level(high frequency update)。这种工作机制保证了,high frequency的descriptor 更改不会影响到 low frequency descriptor 的 resources。
Shaders with SPIR-V
在Vulkan,唯一能够制定shaders或者compute kernels是通过SPIR-V。SPIR-V有以下特点:
- Multiple inputs: SPIR-V producing compilers exist for various source languages, including GLSL and HLSL. These can be used to convert a human-readable shader into a SPIR-V intermediate representation.
- Offline compilation: Shaders/kernels are compiled offline and injected upfront.
- glslangValidator: LunarG SDK provides the glslangValidator compiler, which can be used to create SPIR-V shaders from equivalent GLSL shaders.
- Multiple entry points: The shader object provides multiple entry points. This is very beneficial for reducing the shipment size (and the loaded size) of the SPIR-V shaders. Variants of a shader can be packaged into a single module.
Pipeline management
一个物理设备包括一系类的硬件配置可以用来决定哪些被提交的几何数据将被如何interpreted和drawn。这些设置被总称为pipeline states。他们包括 rasterize state, blend state, 和 depth stencil state; 也包括了所提交的几何体的,和shader用来渲染的图元的topology type(point、line、triangle)。Pipeline里有两种states:dynamic和static。这些pipeline states被用来创建pipeline objects,恰恰这些pipeline objects又是性能的关键。所以我们不想反复的创建这些objects;我们需要创建它们一次,然后复用它们。
Vulkan允许通过pipeline objects配合Pipepline Cache Object(PCO)和Pipeline layout一起来控制管线的states。
名词解释:
*Pipeline objects: Pipeline creation is expensive. It includes shader recompilation, resource binding, Render Pass, framebuffer management, and other related operations. Pipeline objects could be numbered in hundreds and thousands; therefore, each different state combination is stored as a separate pipeline object.*
*PCO: The creation of pipelines is expensive; therefore once created, a pipeline can be cached. When a new pipeline is requested, the driver can look for a closer match and create the new pipeline using the base pipeline.*
*Pipeline layout: Pipeline layouts describe the descriptor sets that will be used with the pipeline, indicating what kind of resource is attached to each binding slot in the shader. Different pipeline objects can use the same pipeline layout.*
在pipeline的管理阶段,会发生以下的操作:
Application 把shader 编译成了SPIV-V的格式 并且在pipeline shader state里指定了其细节。
descriptor 帮我们把这些资源连接到shader。App 从descriptor pool那里分配了descriptor set,并把incoming 或 outgoing resources 连到shader里所的binding slots上。
App 创建pipeline objects,这些object包含了 static and dynamic state configuration to control the hardwre settings. The pipeline should be created from a pipeline cache pool for better performance.
5. 指令记录
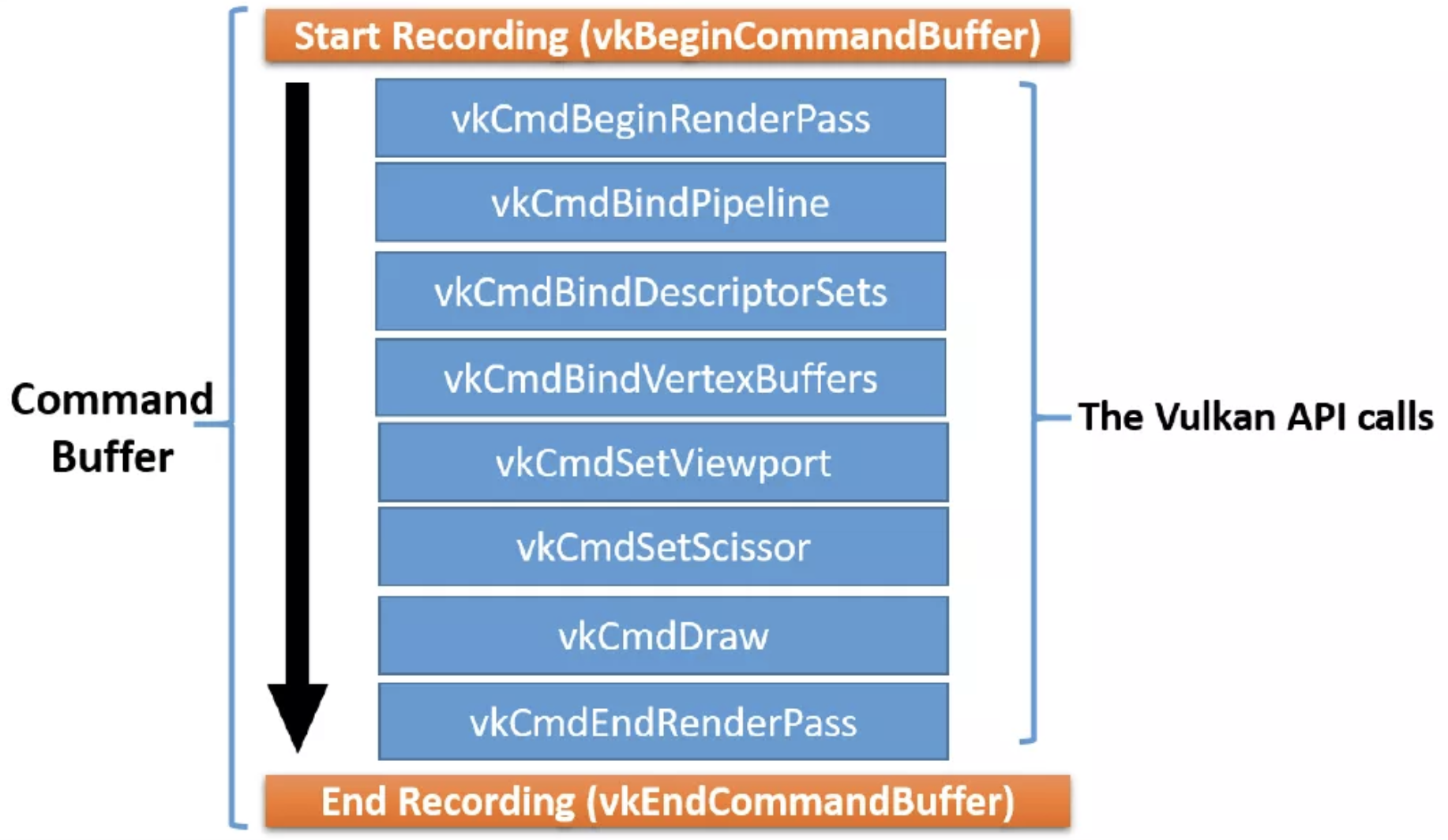
Recording commands 就是形成command buffer 的过程。Command buffers 是从command pool memory 里创建出来的。 在App给定的开始和结束的范围内,command buffer 就会通过被提供comamnds来被记录下来。 下图表示了一个command buffer记录的过程:
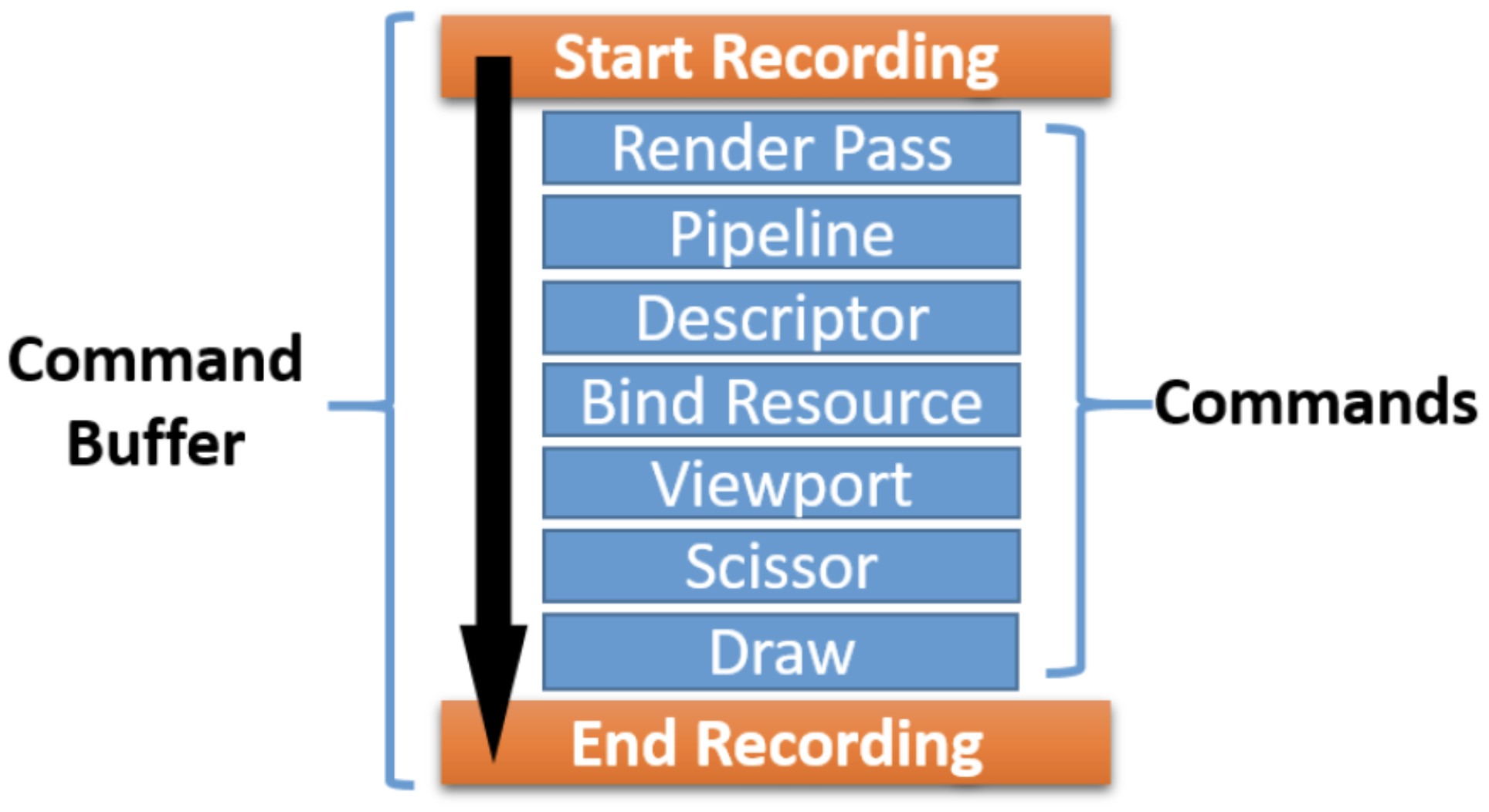
具体的Drawing包含以下的部分:
Scope: The scope defines the start and end of the command buffer recording.
Render Pass: This defines the execution process of a job that might affect the
framebuffer cache. It may comprise attachments, subpasses, and dependencies between those subpasses. The attachment refers to images on which the drawing is performed. In a subpass, an attachment-like image can be subpassed for multisampling resolve. Render Pass also controls how the framebuffer will be treated at the beginning of the pass: it will either retain the last information on it or clear it with the given color. Similarly, at the end of the Render Pass, the results are going to be either discarded or stored.
Pipeline: This contains the states’ (static/dynamic) information represented by a pipeline object.
Descriptor: This binds the resource information to the pipeline.
Bind resource: This specifies the vertex buffer, image, or other geometry-related information.
Viewport: This determines the portion of the drawing surface on which the rendering of the primitives will be performed.
Scissor: This defines a rectangular space region beyond which nothing will bedrawn.
Drawing: The draw command specifies geometry buffer attributes, such as the start index, total count, and so on.
每一个Command Buffer的创建都是非常昂贵的。如果同样的工作将用在多个frames上,那么command buffer是可以被复用多次的。CB 可以不需要被record而直接提交。而且,多个command buffers可以被同时,被多个threads制造出来。
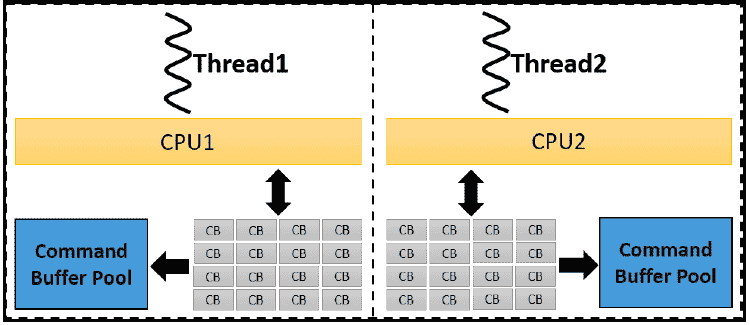
每一个thread 调用一个单独的command buffer pool来分配一个或多个CBs。
6. 指令提交
当完成了command buffers 的创建, 他们就可以被提交到queue上进行下一步处理。Vulkan 提供了不同的queues,例如:graphics, DMA/transfer or compute queues. Queue 的选择决定于其queue的天然属性。例如,跟graphics相关的任务必须提交到graphics queue上;compute operations相关的应该提交compute queue。 被提交的jobs 会被异步地执行。Comamnds buffers 可以被推送到多个各自的compatible queues 来进行parallel execution。App要对所有的command buffers 之间的同步 或 queues之间的同步负责,甚至是对host 和 devcie 两者之间的同步也要负责。
Commands 的提交执行了如下的工作:
- Acquiring the images from the swapchain on which the next frame will be drawn
- Deploying any synchronization mechanism, such as semaphore and fence required
- Gathering the command buffer and submitting it to the required device queue for processing
- Requesting the presentation of the completed painted images on the output device
总结
导读1主要Vulkan的一些关键名字,和大颗粒度的工作模式。这个模式包括了6个步骤,并以此介绍了每个步骤里发生了什么,都用到了那些元素。最后读完本篇,闭眼思考以下几个问题,看看你是不是能回答上来?
- 本文在Vulkan里提到的pipeline 跟 GLES 提到的图形学里的pipeline有区别吗?
- Command buffer 跟 job descriptor 有什么区别?
引用: 《Learning Vulkan》
 wechat
wechat alipay
alipay