Vulkan 导读2: Command Buffer 和内存管理
导读2 主要是讲解第五章,之所以跳过2,3,4章是因为这三章关键概念很少,更多的是围绕Vulkan初始化阶段的准备工作。第五章重点讲解了CB和内存的概念,值得对其细节进行整理。
一个command buffer就是a collection of commands. Command buffer 会被提交到一个合适的 hardware queue 让GPU来处理。driver会fetches和validates并compiles这些command buffers,然后再把它们交给GPU来处理。这一章节主要围绕command buffers 和 memory allocation的讲解了以下topics:
- Getting started with command buffers
- Understanding the command pool and command buffer APIs
- Recording command buffers
- Implementing the command buffer wrapper class
- Managing memory in Vulkan
Getting started with command buffers
名词解释
Command Buffer:a command buffer is a buffer or collection of commands in a single unit.
一个CB 记录了多个可以被App调用和执行的Vulkan API commands。CB一旦被baked后,是可以反复使用的。CB们按照App的调用commands的次序来依次记录commands。这些commands是用来承载不同类型的jobs。这些jobs包括:binding vertex buffer, pipeline binding, recording Render Pass Commands, setting viewport and scissor, specifying drawing commands, controlling copy operations on imag and buffer contents 等。
Command Buffer 有两种:
- Primary command buffers:这种buffer是SCB的owners,并负责执行SCB。PCB是可以被直接提交到queues上。
- Secondary command buffers:SCB是通过PCB来执行的。他们不可以直接被提交到queues上。
一个APP可能会有成百上千个CB。由于数量巨大,所以CB都是通过command pool来创建的, CB本身是无法直接被创建的。
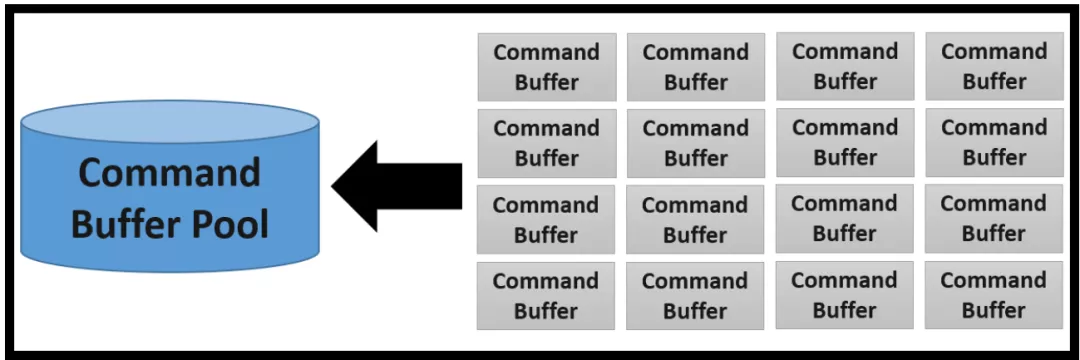
CB是persistent的;它们一旦被创建,就可以被持续地复用。如果一个CB不再有用了,它也可以通过reset command来被renew,然后为下一个recording做好准备。这种做法跟“destroy 再create”的做法比就显得更加高效,
显式同步(Explicit Synchronization)
CB 是由每一个thread所负责的 command buffer pool来创建的。这种做法避免了不同threads之间需要显式地同步去创建CB。但是App必须要对在不同的threads之间共用的CBs做同步不管理。
书中用了一段话比较了OpenGL跟Vulkan两者,把CB提交给GPU过程的区别。值得留意:
*”Another differentiation is the submission of the command buffers in OpenGL: command* buffers are pushed behind the scenes and are not in control of the application. An application that submits the commands has no guarantee when those jobs will be executed. This is because OpenGL executes command buffers in batches. It waits for the commands to build the batch and then it dispatches them together. On the other hand, Vulkan gives explicit control to the command buffer to allow the processing up front by submitting it to the desired queue.” P120, 《Learn Vulkan》
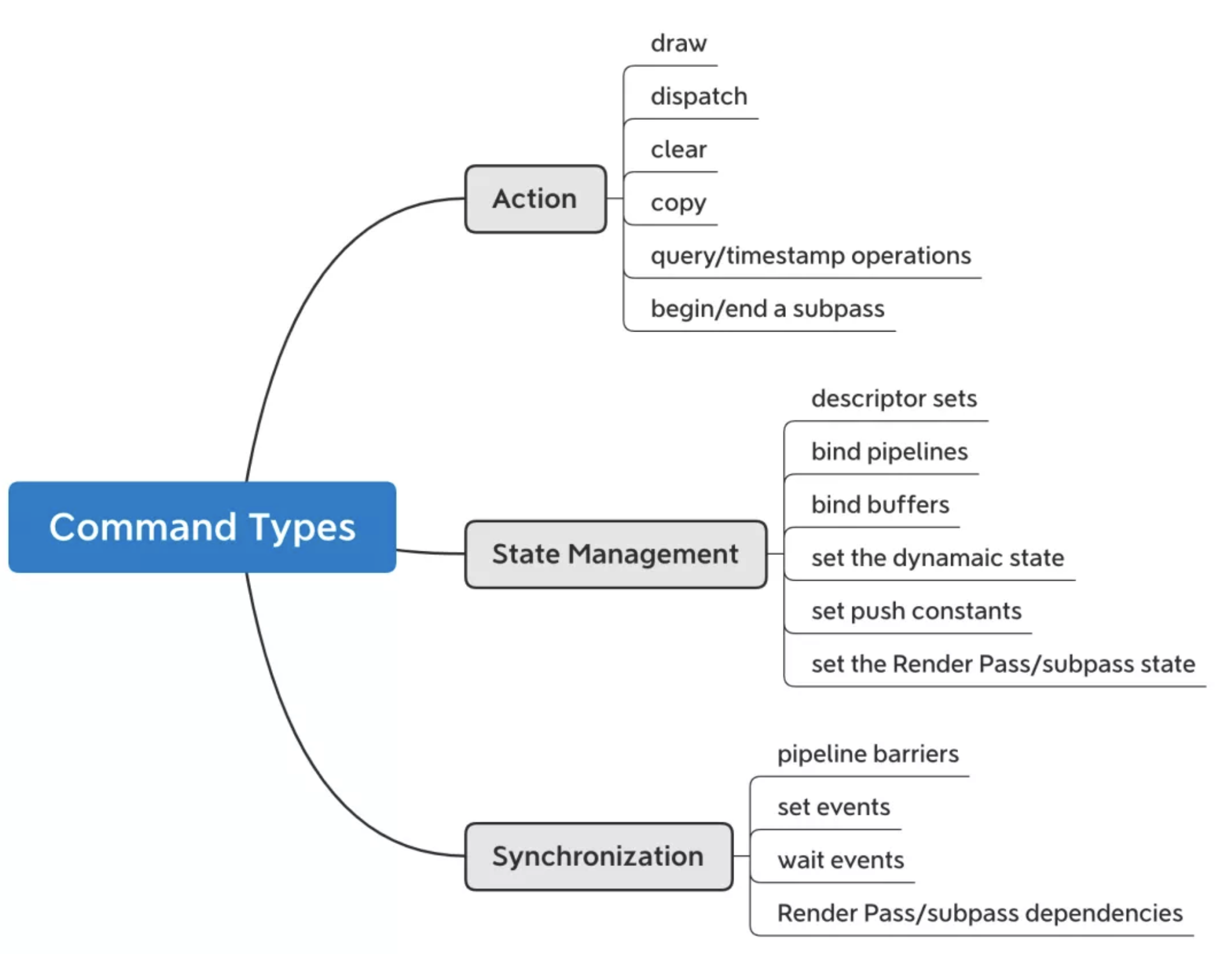
CB 包含了很多个 commands。 这些Commands可以归类为三种:
- Action: This command performs operations such as draw, dispatch, clear, copy,query/timestamp operations, and begin/end a subpass
- State management: This includes descriptor sets, bind pipelines, and buffers, and it is used to set the dynamic state, push constants, and the Render Pass/subpass state
- Synchronization: These commands are used for synchronization: pipeline barriers, set events, wait events, and Render Pass/subpass dependencies
Command Buffer and Queues
CB被提交到 hardware queue后会被异步处理掉。 队列提交可以通过batching CBs来一次完成。Vulkan有一种deferred command model:它可以让CB里对draw calls的收集和提交分别作为两个不同的operations来单独处理。这种做法方便了App可以在大部分场景下针对submission 做出适当的优化, 而这恰恰是OpenGL很难做到的。
Vulkan 提供对硬件queue的逻辑view。每一个逻辑view都关联着一个hardware queue。 一个单一的hardware queue可以用多个逻辑queues。
The Order of Execution
CBs 可以被提交一个single queue或者多个queues上:
- Single queue submission: Multiple command buffers submitted to a single queue may be executed or overlapped. In single queue submission, a command buffer must obey the order of the execution of operations as per the command order and the API order specification. This book only covers the submission commands used for vkQueueSubmit; it does not cover sparse memory binding command buffers (through vkQueueBindSparse).
- Multiple queue submission: The command buffers submitted to multiple queues may be executed in any order unless explicit ordering constraints are applied through the synchronization mechanism via semaphores and fences.
Recording Command Buffers
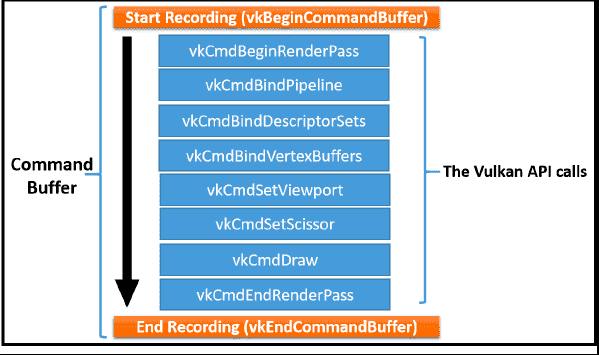
一个CB是通过vkBeginCommandBuffer()和 vkEndCommandBuffer()这两个 APIs 来记录的。这两者之间的scope就是具体的Vulkan commands 被记录的范围。下图显示了一个Render Pass Instance在这两个API之间被记录的过程:
Queue Submission
当一个CB完成记录后,它就可以被提交到一个queue上了。vkQueueSubmit() API 用来把一个CB或者在多个CB提交到正确的queue上。
Queue Waiting
当CBs被提交到queue后,App要等待所提交的工作被完成,才可以接受一下个batch。等待queue的API 是 vkQueueWaitIdle() API。
Managing Memory in Vulkan
Vulkan 将内存分成两种:host memory 和 device memory。host memory被device memory 慢,但是可用的地方比较多。device memory 对GPU可见,所以更快。
Host Memory
书中段落开头一段话很重要,摘要如下:
“Vulkan makes use of host memory to store API internal data structures in the implementation. Vulkan provides allocators, which allow an application to control memory allocation on behalf of host memory. If the application does not use allocators, then the Vulkan implementation uses a default allocation scheme to reserve a memory slot for its data structures.” (p137, 《Learn Vulkan》)
这段话可以总结为以下信息:
- host memory 是用来存储API internal data strucutures
- App通过Allocator来分配和创建host 的memory
- 如果APP不通过allocator,那么Vulkan使用默认alllocation scheme来为data structures保留内存的slot。
至于内存的分配管理则是用callback来完成的:
“Host memory is managed by the VkAllocationCallbacks control structure, which is passed to Vulkan APIs for custom management of host memory.”
Device Memory
书中段头解释的很清楚:
“Device memory is GPU memory that is visible to the physical device. The physical device can read its memory regions directly. Device memory is very close to the physical device, and thus provides faster performance than host memory. Image objects, buffers objects, and uniform buffer objects are all allocated on device memory.” P139,《Learn Vulkan》
App 有责任通过调用 vkGetPhysicalDeviceMemoryProperties()API 来查询物理设备上可用的memory heaps 和 meomory properities,并更好的分配这些资源。
总结
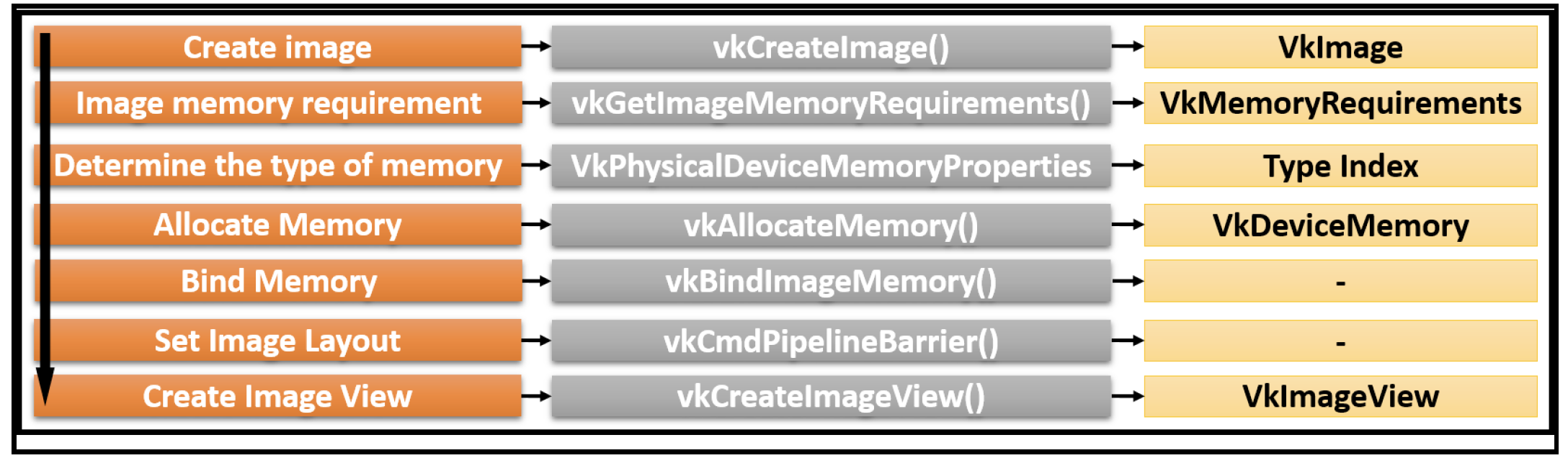
书中在这一章节介绍了CB和meomory allocation, 并给出了API的调用细节,导读里我没有针对具体的代码细节展开,代码可以自己看,很容易理解。Vulkan所分配的资源可以分为两种:buffers 和 images。我们会在导读3介绍images resources;然后在导读4里介绍 buffer resource,Render Pass,Framebuffer 和 shaders。所以导读4也将是最重要的一章!
引用: 《Learning Vulkan》
 wechat
wechat alipay
alipay