GPU 计算的发展历程
人类似乎对计算有着天然的追求,几乎所有的自然语言 都至少有“1”和“2”的数字概念。文明史其实也是一部计算的历史,人类总是在追求更强的计算能力。公元前 3000 年古巴比伦就发明了算盘,1822 年查尔斯·巴贝奇设计出第一台机械计算机。1936 年图灵提出了通用计算机模型,1943 ~ 1945 年第一台电子计算机在宾夕法尼亚大学诞生,标志着计算机时代的来临。20 世纪 60 年代集成电路技术的发展为计算硬件注入了空前的活力。1971 年第一款通用微处理器芯片 4004 的出现标志着人类进入个人计算机时代。20 世纪八九十年代是计算机体系结构的黄金时期,随着流水线和超标量等指令间技术的不断深入,CPU 性能不断提升,而编程模型不需要任何改变就可以获得更高性能。2000 年以后,一方面指令间并行技术发展逐渐遭遇瓶颈,单核 CPU 的性能趋于饱和。另一方面,半导体工业仍然能够提供更高的集成度。针对这种形式,直观的解决方法是在单个集成电路上部署多个处理器,所以多核(几个到几十个内核)处理器甚至众核(几百个到上千个内核)处理器应运而生。与单核处理器主要利用指令间并行性不同,多核和众核处理器依赖线程级与数据级并行性来提高处理能力,换言之,需要程序员设计并行算法并且在代码中指定并行的方式。主流计算工具开始实现全面并行化,这是人类计算史上的第一次,因此具有深远的意义。
在过去短短几年中,并行处理器无处不在,即使是手机的应用处理器,也会装备多个内核。然而,并行算法设计、程序开发和编译技术的发展却滞后很多。这一方面是由于人类思维方式组织在顺序模型中(虽然执行基础是高度并行的),直接进行并行思维非常困难;另一方面是由于现有技术储备不足,虽然并行计算已经过多年发展,但主要用在高性能计算领域,其问题、方法甚至程序员群体都与当前有着巨大的区别。正如《量化计算机体系结构》的两位作者——计算机体系结构大师和诺依曼奖获得者 John L. Hennessy 和 David Patterson 指出的那样,正如 50 年前的编程危机,易于编程的高性能并行处理器体系结构和并行编程模型是计算机科学与技术史上面临的最大挑战之一[1]。
严峻的挑战也会带来崭新的机会。50 年前的编程危机催生出高级编程语言,而现在也能看到大量新型计算机体系结构和编程模型在不断涌现。在这本书里,我们关注图形处理器
(GPU)。当前的 GPU 一般以单片集成电路的形式出现,同时也是单片处理能力最高的处理器。顾名思义,图形处理器是为图形应用这一类特殊计算而生的,那么,GPU 是怎样成为通用计算处理器的呢?本章首先扼要回顾计算机图形学的发展,从中整理出 GPU 的概念;接下来整理 GPU 的发展脉络;最后介绍 GPU 通用计算的发展历程。
计算机图形学的发展
图形处理器是计算机图形学(Computer Graphics,CG)高度发展的结果。计算机图形学研究用计算机生成适合人眼观看的二维或三维图像表征。由于通过眼睛采集图像是人类感知信息最重要的方式,所以图形显示是计算机信息处理过程中人机交互的核心手段。自 1960
年“计算机图形学”术语的出现,该学科已经历经 50 年的发展。以计算机游戏和电影制作为代表的娱乐业应用、以工程 CAD 为代表的可视化应用,以及各类图形界面应用取得了长足进步,已经并且继续深刻地改变着人类生活、工作和娱乐的方式。由于人眼对图形细节有着极高的分辨能力,随着计算机技术的高速发展和人类对用户体验的不断追求,计算机图形学至今仍然是计算机科学研究的热点。
表 1-1 列出了计算机图形学发展历程中的主要里程碑。令人惊奇的是,早在 1944 年, MIT 开展的“ Whirlwind”计算机项目中就已经出现了现代计算机图形学的关键概念。该计算机用于冷战时期的防空作战指挥,对快速、有效的图形交互具有强大需求,开始使用阴极射线显示器、光笔等现代图形交互手段。在此基础上,MIT 又设计了 TX-0 和 TX-2 计算机, 当时还是博士研究生的计算机图形学大师 Ivan Sutherland 为 TX-2 设计了 Sketchpad 图形交互工具。如图 1-1 所示,Sketchpad 允许使用光笔在显示器上绘制和操作图形。Sketchpad 包含现代计算机图形学的几乎所有核心概念。因此,Ivan Sutherland 被认为是计算机图形学的祖父级人物。
| 时间 | 计算机图形学发展的重要成就 |
|---|---|
| 1944 年 | MIT 开展的“Whirlwind”项目首次系统化研究实时计算机图形显示 |
| 1960 年 | “计算机图形学”术语出现 |
| 1962 年 | 第一个多玩家计算机游戏 Spacewar |
| 1963 年 | Ivan Sutherland 发明 Sketchpad |
| 1965 年 | 首次计算机艺术展在斯图加特和纽约举办 |
| 1967 年 | ● Coons Patch 复杂曲面建模算法提出 ● NASA 设计了第一个全彩色实时飞行模拟器 |
| 1968 年 | 第一家计算机图形技术公司 Evans & Sutherland 成立 |
| 1968 年 | 首届计算机图形学会议(SIGGRAPH)召开 |
| 1970 年 | 随机访问存储器和光栅化显示器诞生 |
| 1973 年 | 多维可视化,Phong 渲染算法提出 |
| 1974 年 | Z-Buffer 算法,纹理映射算法提出 |
| 1980 年 | ● 首届欧洲图形学(Eurographics)会议召开 ● 光线追踪算法提出 ● 迪斯尼制作第一部大量使用计算机合成图像(超过 20 分钟)的电影《TRON 》 |
| 1982 年 | ● Silicon Graphics 公司设计硬件图形引擎(Geometry Engine) ● 工业光魔(Industrial Light and Magic)公司制作第一部计算机动画电影《Startrek 》 ● 3D 计算机辅助设计软件公司 Autodesk 成立 |
| 1984 年 | ● 第一家专攻计算机动画电影的公司 Pixar 成立 ● Apple 公司发布第一台拥有图形界面的个人计算机 |
| 1985 年 | ● 2D 图形标准 GKS(graphical kernel system)发布 ● ATI 公司(后来被 AMD 公司收购)成立 |
| 1987 年 | ● 美国自然科学基金开始专门资助图形学研究 ● Marching Cubes 可视化算法提出 |
| 1988 年 | ● 2D 图形标准 PHIGS 发布 ● 3D 图形标准 ISO GKS-3D 发布 |
| 1989 年 | ● 第一部真实 3D 角色电影《Abyss》 ● 3D 渲染软件 Renderman 公开发布 |
| 1991 年 | 数据可视化工具 OpenDX 推出 |
| 1992 年 | Silicon Graphics 公司推出 OpenGL 标准、图形流水线标准化 |
| 1993 年 | NVIDIA 公司成立 |
| 1994 年 | Sony 公司的 Playstation 游戏机和任天堂的 N64 游戏机问世 |
| 1995 年 | ● Microsoft 公司定义 Direct3D 图形接口 ● 3D 第一人称设计游戏 Quake 发布 |
| 1996 年 | 3DFX Voodoo 图形加速器获得巨大成功 |
| 1997 年 | Titanic 获得奥斯卡特效奖,其中大量使用了人群仿真和流体力学仿真 |
| 2000 年 | Sony 公司的 Playstation 2 问世 |
| 2001 年 | Imagination 公司设计 PowerVR MBX GPU 内核,并在移动 GPU 市场取得成功 |
| 2002 年 | ● Microsoft Xbox 游戏机出现 ● 奥斯卡首次颁发最佳动画形象奖并由 Shrek 获得 |
| 2009 年 | 第一部大量使用面部表情捕捉动画技术的电影《Avatar》 |
1960 ~ 1980 年是计算机图形学的“少年期”,图形渲染的基本理论在这 20 年得到充分发展,如曲面建模、着色渲染、Z-buffer 可见度判断、光线追踪和纹理映射等方法都是在这段时期形成的。同时,计算机图形学的主要应用也涌现出来:最早的带有图形特征的计算机游戏 Spacewar 在 1962 年出现 ,1967 年 NASA 设计了第一个全彩色实时飞行模拟器,1980 年迪斯尼制作的电影《TRON》包含了超过 20 分钟的计算机合成动画。同期的硬件重大发明是随机访问存储器(Random Access Memory,RAM)和光栅化显示器,这些硬件技术的进步使得大众消费级别的高性能图形显示成为可能。在这段时间内,计算机图形学学术圈也逐渐形成:1968 年首届计算机图形学会议(SIGGRAPH)召开,至今其仍是该领域最为重要的学术会议和相关技术展示平台,与 1980 年出现的欧洲图形学会议以及此后出现的 SIGGRAPH Asia 并称为计算机图形学的三大会议。

20 世纪八九十年代是计算机图形学的“青年时代”。首先,计算机图形工业逐渐形成。著名的图形特效制作公司工业光魔、动画电影制片厂 Pixar 成立,图形 CAD 软件公司AutoCAD、图形硬件制造商如 SGI、显卡制造商纷纷出现。Pixar 设计了著名的专业渲染软件 Renderman,几乎成为电影级渲染的标准;美国电影工业开始大量使用计算机图形学技术, 其标志性电影《Titanic》大量使用人群仿真和流体力学仿真方法制作电影特效,并且于 1997 年获得奥斯卡特效奖。继 1984 年 Apple 公司的个人计算机出现后,具有图形化人机界面的个人计算机也得到了普及,Sony 公司和任天堂也分别推出了著名的游戏机平台 Playstation 和N64。图形应用对硬件性能要求极高,早期的图形处理硬件在这样的大背景下应运而生,SGI 首先设计了著名的 Geometry Engine。此后一系列专注于图形硬件的公司如 ATI、S3、3DFX、NVIDIA 就像雨后春笋般出现了,纷纷推出专用图形处理芯片。由于此时图形硬件尚不具备编程能力,因此一般被称为图形加速器,以显卡的形式体现功能。1991 年 S3 公司首先设计出第一块 2D 图形加速芯片,1995 年 NVIDIA 公司设计首个 3D 图形加速芯片 NV1,1996 年3DFX Voodoo 图形加速器在市场上取得巨大成功。从这时开始,高端图形显示硬件形成了以显卡作为功能载体的基本模式,而显卡功能以图形加速芯片为核心,辅之以图形存储器。此外,IBM 公司设计了专用数据可视化工具 OpenDX,标志着一个新的图形学应用出现。随着工业化程度的深入,工业界和学术界提出了图形处理的标准化需求。早期的标准包括 2D 图形标准 GKS、PHIGS 和 3D 图形标准 ISO GKS-3D,而随后 SGI 公司提出的 OpenGL 则成为事实上的工业标准,Microsoft 公司也推出了 Direct3D,形成了图形标准的另一大阵营。OpenGL 和 Direct3D 的出现标志着计算机图形操作的标准化,使得图形应用跨平台兼容成为可能,极大加速了图形软硬件技术的发展,成为今天所有图形软件和硬件的基础。

2000 年后,计算机图形学进入加速发展阶段。在硬件方面,自 2001 年 NVIDIA 公司推出第一个可编程渲染图形处理器 GeForce 3 以来,图形处理器的概念正式出现。此后,计算机图形硬件市场形成了 NVIDIA 公司、ATI 公司(后来被 AMD 公司收购)和 Intel 公司三雄并立的局面。其中 Intel 公司专注于集成显卡,在中低端市场具有显著优势,而 NVIDIA 公司和 ATI 公司则在高端独立显卡市场展开白热化竞争,双方的竞争一度使得 GPU 芯片集成度的上升速度超过了摩尔定律。与此同时,移动平台同样需要 GPU。类似于早期计算机的 GPU 市场,移动 GPU 的竞争更加激烈,目前主要的移动 GPU 供应商包括 Imagination、QualComm、NVIDIA、ARM 等多家公司,其中 Imagination 和 QualComm 的市场份额较大, 但并不具备绝对优势。另一方面,随着硬件技术的进步,使得全局光照和物理仿真等技术能够应用在各种图形中。好莱坞大片越来越依靠计算机制作的特效,动画人物的衣物、头发、皮肤、表情等普遍通过物理仿真技术生成,而光线追踪等物理真实渲染技术也被大量使用。2002 年开始,奥斯卡新设的一个奖项——最佳动画形象奖由 Shrek 获得。2009 年上映的
《 Avatar》是面部表情捕捉、光线追踪、物理仿真等技术的集大成体现。图 1-3 是《 Avatar》中使用光线追踪技术制作的一个镜头,其中远处的植被和动物具有极其真实的光照效果。

图形流水线
OpenGL 和 Direct3D 都定义了图形流水线(graphics pipeline)概念,包括一系列计算机图形显示过程中必须执行或可选的图形操作。目前,所有 GPU 的操作都是围绕图形流水线设计的。因此,接下来将分析图形流水线的主要操作,从中了解图形应用对 GPU 硬件体系结构提出了怎样的要求。当前的图形流水线非常复杂,下面以图 1-4 中只包含基本操作的简化图形流水线来说明。
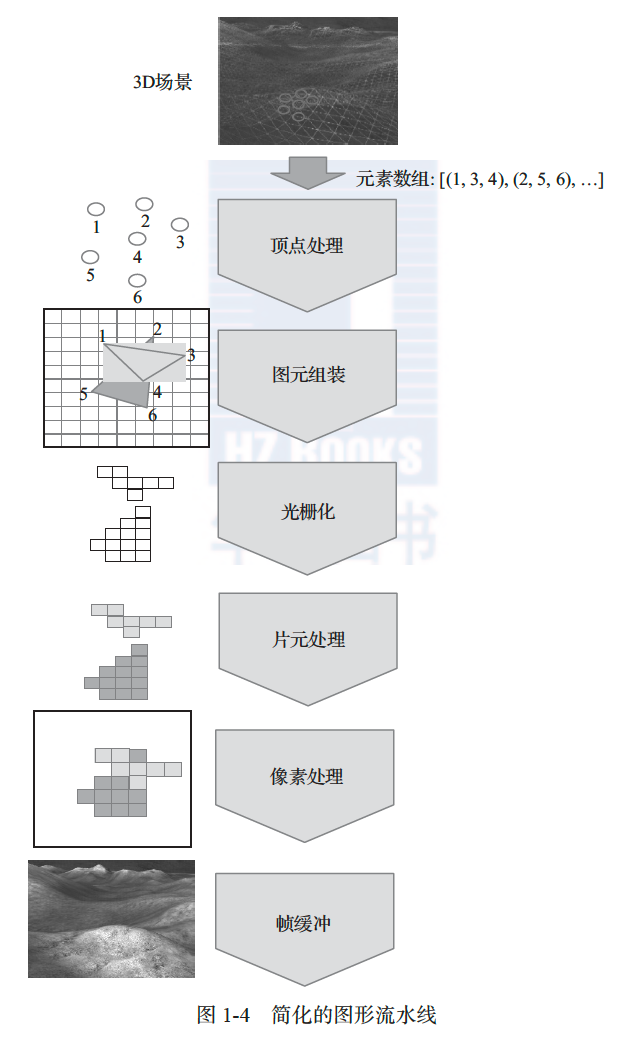
一般来说,应用程序中需要现实的场景由 CPU 产生,包含图形对象的形状、材质及光源信息等。图形对象的形状可以任意复杂,计算机图形学发展了以基本多边形网格
(mesh)近似复杂形状的方法,从而能够以有限的空间复杂度逼近真实形状。将图形对象切割为三角形或其他多边形网格的工作一般由 CPU 负责。该网络中的基本图形元素称为图元
(primitive),本书只考虑最为常见的三角形网格。CPU 将需要显示的三角形网格以元素数组的形式传送给 GPU,该数组的每个元素为一个三角形,由三个顶点表示。各个顶点的三维坐标和图形操作指令同时也传递给 GPU。在通用计算机平台(服务器、台式机或笔记本电脑) 上,CPU 和 GPU 普遍使用 PCI Express 总线传递信息;在移动平台(手机或平板电脑)上, 以上信息由相应的数据总线(如 ARM 公司的 AMBA 总线)传递。
图形数据传递到 GPU 后首先进行顶点处理(vertex processing)。顾名思义,这一级操作针对顶点进行,包括坐标变换(transformation)和光照(lightning)两个范畴的操作,因此经常被简称为 T&L。前者包括一系列空间坐标变换以及从三维空间到二维显示屏幕的投影映射,后者根据场景设置决定每个顶点接受的光照。在早期图形硬件中,这个步骤的操作是固定的,按照坐标转换、顶点光照和投影变换的固定属性进行。现在几乎所有的 GPU 都支持可编程顶点处理,相应的程序称为顶点渲染程序(vertex shader)。注意各个顶点的操作没有依赖关系,可以并行进行。
接下来的步骤是图元组装(primitive assembly),将各个顶点重新组合为基本图元,并且根据屏幕视野将不可见的图元裁剪掉。由于一般都使用三角形作为基本图元,所以这一步骤也经常被称为三角形设置(triangle setup)。几何渲染(geometry shading)是图元组装之后的一个可选步骤,以图元作为单位处理。
接下来 GPU 对这些图元进行光栅化操作,即空间采样,将图元分解为像素大小的元素, 称为片元(fragment)。片元处理(fragment processing)是图形流水线中操作最复杂、计算量最大的一个步骤,因此该步骤是 GPU 中最早实现可编程化的部分。必须注意的是,每一个图元都会产生自己的一组片元。来自不同图元的片元可能在二维显示屏上重叠,但是在这一阶段所有可见或不可见的片元都被平等对待。这当然是简化处理方式,引入了冗余后,该问题只有在使用光线追踪算法时才能得到完美解决。片元处理根据顶点光照结果进行内插,以决定当前位置的光照;同时一般还要进行纹理映射(texture mapping)操作,将事先存储的纹理像素复制到片元。该步骤为每一个片元产生渲染结果和深度值。不同片元的处理可以完全并行化,GPU 普遍配置多个片元处理单元进行并行处理。较早的 GPU 硬件中,片元的渲染结果完全通过对顶点结果进行内插获得,所以片元处理与光栅化经常合成一个步骤,称为光栅化和内插。
图形流水线的最后一个阶段是像素处理,现代 GPU 通常配置大量渲染输出单元(render output unit)并行完成这一步骤。渲染输出单元一般被称为 ROP(raster operation pipeline)。该步骤的主要任务是决定最终的显示结果。由于多个片元可能对应同一像素,因此需要由Z-buffer 等可见性算法决定最终渲染结果,并送到帧缓冲(frame buffer)输出。帧缓冲用于显示存储器中直接对应显示输出的地址空间正好存储一帧的显示结果。
图 1-4 是简化的图形流水线,而 OpenGL 4.0[3]定义的图形流水线要远为复杂,如图 1-5 所示。其中,较深颜色方框表示缓冲或存储器,较浅颜色方框表示可编程模块,其他方框表示固定功能模块。有兴趣的读者可以查阅相关标准和教科书了解现代图形流水线的细节。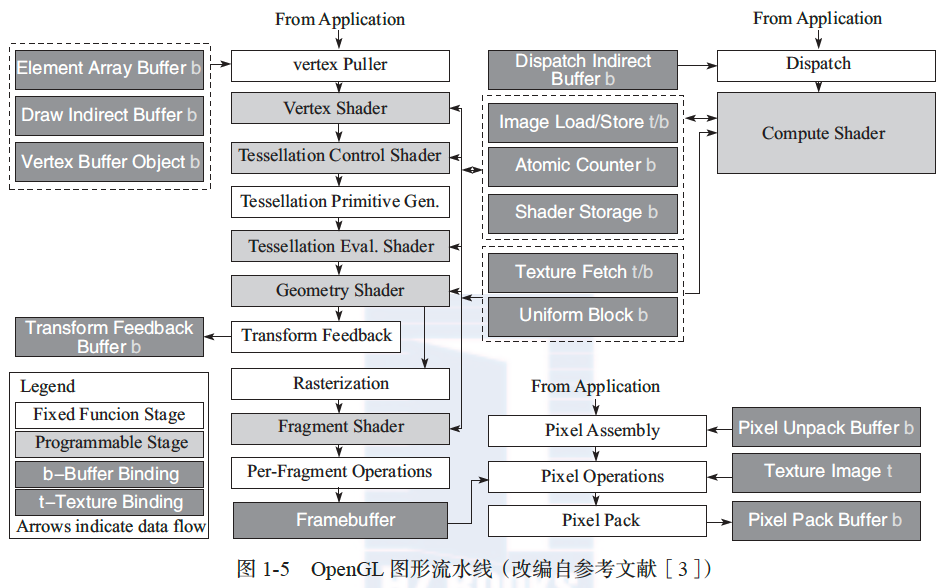
GPU的发展过程
虽然专用图形硬件从 1944 年 MIT 的 Whirlwind 项目就开始出现,并于 20 世纪 80 年代逐渐成形,但图形处理器或 GPU 这个名词直到 1999 年才由 NVIDIA 公司创造,此后逐渐发展成为同时具备高速图形处理能力和通用计算能力的强大硬件。表 1-2 列出了 GPU 发展史上的重要里程碑。
表 1-2 GPU 发展史的重要里程碑
| 时间 | GPU 发展史中的重要成就 |
|---|---|
| 1944 年 | MIT 开展的“Whirlwind”项目首次设计实时图形显示硬件 |
| 1982 年 | 以 Geometry Engine 为代表的专用图形处理硬件芯片出现 |
| 1985 年 | 图形加速硬件出现在大规模市场产品(如 Commodore 公司的 Amiga 计算机)中 |
| 1991 年 | S3 公司设计首个 2D 图形加速芯片 S3 86C911 |
| 1995 年 | NVIDIA 公司设计首个 3D 图形加速芯片 NV1 |
| 1999 年 | NVIDIA 公司提出 GPU 概念,其 GeForce 256 GPU 首次实现基于硬件的变换与光照(transform and lighting) |
| 2001 年 | NVIDIA 公司推出第一个可编程渲染图形处理器(GeForce 3) |
| 2005 年 | ATI 公司推出首个统一渲染图形处理器,用于 Xbox 360 |
| 2006 年 | NVIDIA 公司推出首个针对计算机统一渲染图形的处理器 |
| 2011 年 | AMD 公司推出 CPU / GPU 融合处理器(APU) |
1980 年以前的图形硬件都只具备固定的图形功能,其中多数只支持帧缓冲的功能,因此属于图形加速器范畴,还不能称为 GPU。1980 年后出现了以 IBM Professional Graphics Controller[4]为代表的专用图形卡,用 Intel 8088 芯片实现图形功能,是现代显卡的雏形。1982 年出现的 Geometry Engine[5]和 1985 年出现的 Pixel-Planes[6]是最早的专用图形处理器,开始具备有限编程处理能力。Geometry Engine 拥有图形处理指令集,支持流水线式指令处理。如图 1-6a 所示,其硬件组织为 12 级流水线,其中前 4 个用于顶点坐标变换,中间 6 个用于图形剪裁(即判断图形是否位于用户可见屏幕),最后两个用于投影变换或者按比例伸缩。Geometry Engine 还不是完整的处理器,不具备取指令功能,因此只能作为协处理器工作, 由主处理器向其发送控制指令和数据。图 1-6b 是 Geometry Engine 的芯片管芯照片。该芯片在 1982 年就能够支持 256 彩色、1024×1024 显示分辨率,的确是了不起的成就。虽然单个芯片只能支持流水线式并行,后来的 Reality Engine[7]将 8 个 Geometry Engine 配置在一张显卡上,能够支持数据级并行。Geometry Engine 是顶点处理可编程硬件的先驱,后续像素级处理需要由其他硬件实现。其功能与 Pixel-Planes 芯片[6]正好互补,后者实际上是在帧缓冲存储器上叠加逻辑功能的芯片,能够方便地对多个像素进行各种编程操作.

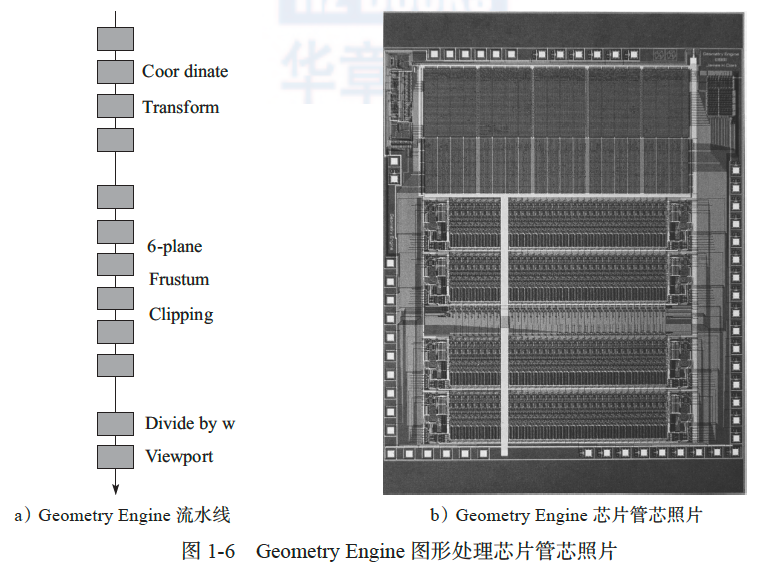
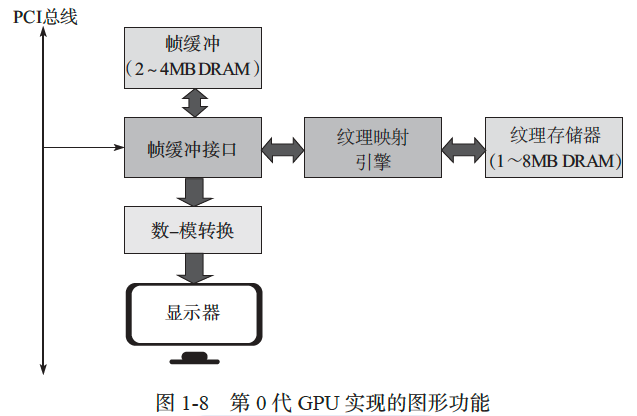
在当时的背景下,Geometry Engine 和 Pixel-Planes 属于高端图形硬件范畴,价格昂贵, 尚不能被大众消费市场接受。但是这些技术为此后 GPU 的发展提供了技术储备,从 1985 年开始,ATI、S3、3DFX、ViewLogic、Matrox、NVIDIA、Imagination、Rendition 等专业图形加速硬件公司如雨后春笋般出现,普遍把目标定位于消费级市场。早期产品大多定位于 2D 显示加速卡,直到 1996 年 3DFX 公司推出 Voodoo 图形芯片组,标志着 3D 图形加速卡市场正式出现。事实上,该芯片组不是单一的处理器,而是由帧缓冲处理芯片、纹理映射芯片和显示数模转换芯片组成的系列。因此,我们将 Voodoo 图形芯片组称为第 0 代 GPU。图 1-7 是使用 Voodoo 图形芯片组的 Diamond Monster 3D 显卡。Voodoo 图形芯片组实现了图形流水线中从光栅化到帧缓冲的功能,顶点处理仍由 CPU 完成并经由 PCI 总线传输给 GPU,如图 1-8 所示。Voodoo 图形芯片组取得了巨大成功,一度占据 80% 以上的相关市场,此后GPU 的发展就是在此技术上沿着图形流水线继续增加功能。但是,3DFX 公司之后的发展并不顺利,2001 年不得不停止运营。不过,3DFX 公司的技术专利被 NVIDIA 公司收购,而核心技术人员之后也加入了 NVIDIA 公司,因此 Voodoo 的血脉通过 NVIDIA GPU 一直保存至今。
20 世纪 90 年代末,GPU 市场逐渐形成 NVIDIA 公司和 ATI 公司双雄争霸的情形。
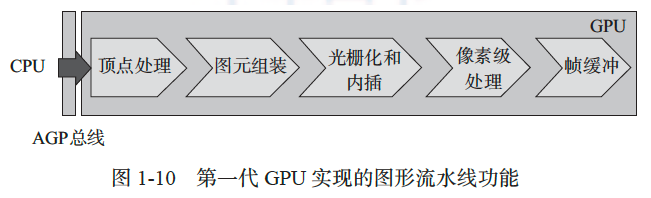
1999 年,NVIDIA 公司设计了 GeForce 256 图形处理器,正式定义了 GPU 这个名词。因此, GeForce 256 图形处理器是当之无愧的第一代 GPU,图 1-9 是采用该 GPU 的显卡。差不多同一时期,ATI 公司也推出了 Radeon 7500 GPU。如图 1-10 所示,GeForce 256 GPU 首次将完整的图形流水线集成到单一芯片上,从 CPU 接收绘图命令和场景数据,并且用性能更好的AGP(advanced graphics port)总线代替了 PCI。也就是说,GeForce 256 集成了顶点处理(即T&L)、图元组装(包括剪裁)、光栅化和像素级处理,支持每秒 1500 万多边形和 48 000 万像素的处理速度,在显示帧速率上 GPU 产品提升了 50%。GeForce 256 的出现第一次使得 GPU 能够用于消费级市场,改变了 GPU 一般用于高端计算机辅助设计应用的局面。应该注意的是,第一代 GPU 仍然只能支持固定功能的图形流水线。有趣的是,GeForce 256 还集成了一个运动补偿单元,以支持视频处理,这也是在 GPU 上集成专用加速硬件的开端。


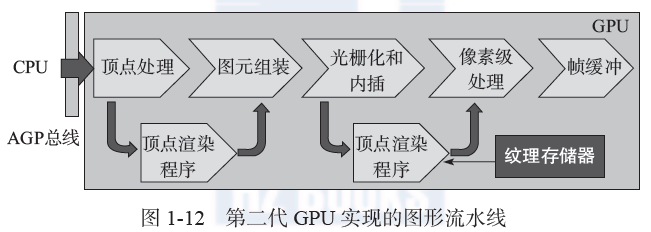
2001 年,真正具有编程能力的第二代 GPU 出现了,代表产品为 NVIDIA 公司的GeForce 3 GPU(内部代号 NV20,如图 1-11 所示)和 ATI 公司的 Radeon 7500 和 8500 GPU。如图 1-12 所示,第二代 GPU 的编程能力体现在顶点处理阶段,GPU 可以接受顶点渲染程序(vertex shader)和片元级渲染程序(fragment shader) 。同时,片元级渲染程序还可以使用专用的纹理存储器。GeForce 3 不仅增加了编程能力,其处理能力也大幅度提高了,支持每秒5000 万多边形和 96 000 万像素的处理速度。可编程渲染程序已经可以支持复杂的动画效果,如脸部的皱纹和水波的涟漪都可以呈现复杂的光照效果。Doom 3 是最早成功利用可编程渲染的游戏,经过全新设计的顶点和片元渲染代码,其图形效果相对早期版本实现了飞跃。

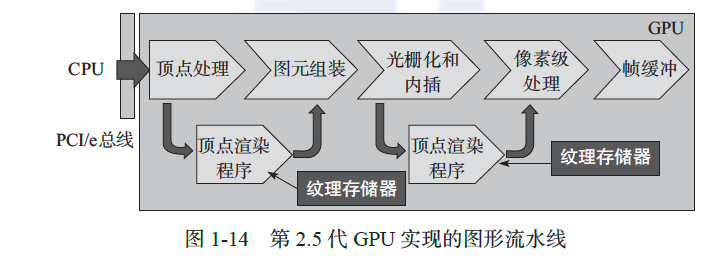
2004 年出现的 NVIDIA GeForce 6 系列 GPU 是对第二代 GPU 的丰富和拓展,因此笔者将其归类为第 2.5 代 GPU。图 1-13 显示的是 GeForce 6800 GPU 的体系结构,图 1-14 是其实现的图形流水线功能,该 GPU 拥有 6 个顶点处理器、16 个片元处理器和 16 个 ROP。其中, 顶点处理器和片元处理器具有完整的可编程功能,能够支持条件和循环编程结构。相比第二代 GPU,GeForce 6800 的顶点处理器也拥有纹理存储器。第 2.5 代 GPU 的峰值计算能力全面超过了同期的 CPU,因此基于 GPU 的通用计算概念也是在这个时期产生的[9]。此时, GPU 拥有顶点处理器和片元处理器两种计算资源,采用不同的硬件体系结构,其中前者为矢量浮点单元,功能相对简单,而后者具有较强的编程能力。因此,这个阶段的通用计算一般使用编程性更好的片元处理器。
早期的 GPU、显卡的型号和命名比较混乱,随着市场的逐渐成形,目前已逐渐形成规律。一般来说,制造商会在研发阶段为每一代 GPU 芯片分配特殊的代号和名字,形成产品后按照性能分级形成新的型号, 相应地显卡还会有自己的代号。例如,NVIDIA 公司的 NV40 GPU 是其研发代号,产品化后根据性能有GeForce 6500、GeForce 6700、GeForce 6800 等多个型号、其中 GeForce 6800 是功能较强的成熟产品,相应显卡有 GeForce 和 Quadro 两个序列,前者针对消费市场,后者针对高端图形应用市场。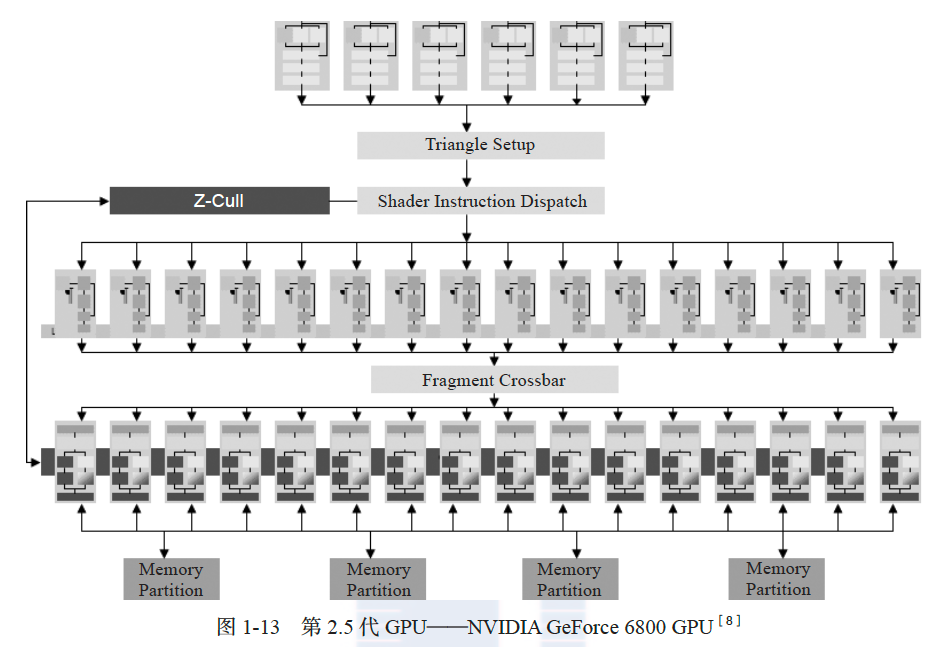
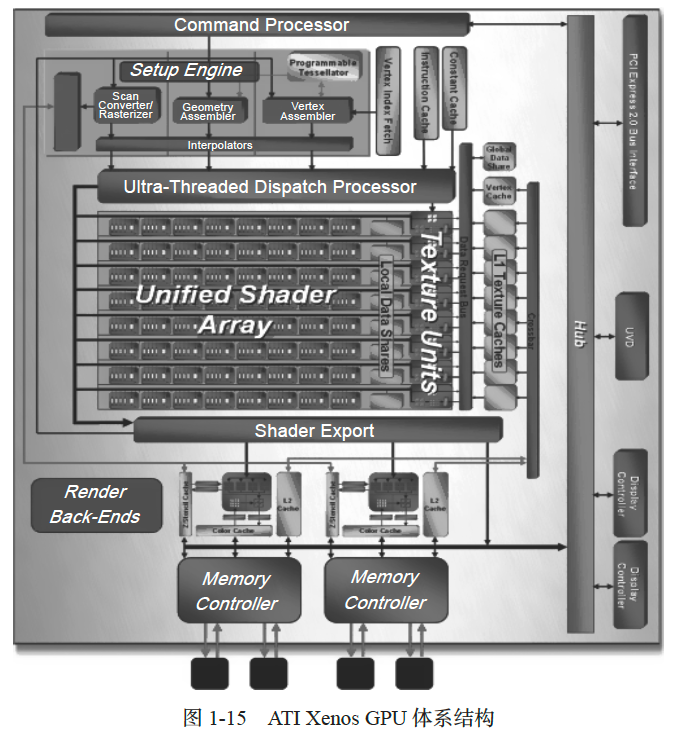
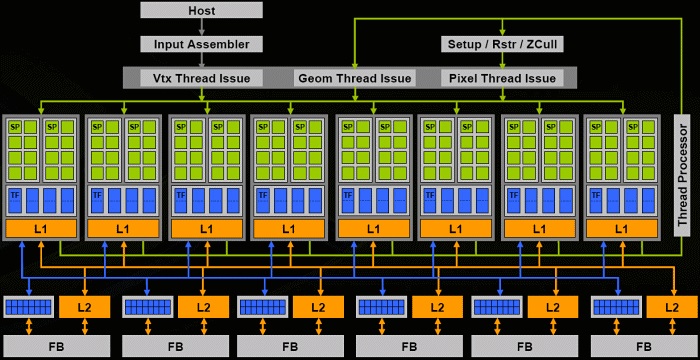
到2005 年,主要的GPU 制造商都使用顶点处理器和片元处理器两种计算资源。然而, 合理配置这两种资源的问题却始终没有得到完美解决。特别是两种处理器数量的最佳比例是 随应用的变化而变化的,因此经常出现一种处理器不够用而另一种处理器闲置的情况。因 此,从2005 年开始,GPU 体系结构方面的最大变化在于引入了统一渲染内核(unified shader processor)概念,即GPU 装备一组完全相同的、具有较强编程能力的内核,根据任务情况在顶点和片元处理任务之间动态分配。最早拥有统一内核的GPU 是ATI 公司为Microsoft Xbox 游戏机设计的Xenos,其体系结构如图1-15 所示。与以往GPU 明显不同的是,Xenos 拥有64 个完全相同的流处理单元(streaming processing units)。每个单元配备5 个计算单元和1 个分支处理部件,以超长指令字(Very Long Instruction Word,VLIW)方式调度执行程序。2006 年,NVIDIA 公司推出G80 处理器,装备GeForce 8000 系列显卡,标志着GPU 全面采用统一渲染内核。从 G80 开始,NVIDIA GPU 体系结构已经全面支持通用编程,同时NVIDIA 公司也推出了著名的 CUDA 编程技术,为 GPU 通用程序设计提供了第一套完整工具。图 1-16 是 NVIDIA G80 GPU 的体系结构,其组织形式比 Xenos 的多一个层次。NVIDIA G80 GPU 拥有 8 个流多处理器(streaming multiprocessor),各自独立执行。每个流多处理器拥有 8 个流处理器(也被称为 CUDA 内核),以 SIMD 方式并行执行。NVIDIA G80 GPU采用硬件多线程技术,多组线程共享一个流多处理器的硬件,分时执行,以隐藏存储器延时。
从此,GPU 设计厂商必须在设计 GPU 时兼顾图形和通用计算的需求。NVIDIA 公司在 G80 之后又推出 G90、Fermi、Kepler 和 Maxwell 等多代 GPU,其通用计算能力越来越强大。ATI/AMD 公司后续推出的 GPU 开始采用新一代图形内核(graphics core next),并且借助 OpenCL 标准的推出,全面支持 GPU 通用计算。特别是在 2011 年,AMD 公司首先将多个 CPU 内核和 GPU 内核集成在同一芯片上,称为加速处理器(Acceleration Processing Unit, APU),从而形成了一类新的处理器。图 1-17 是 AMD Llano APU 的示意图,其中 SIMD 引擎阵列(SIMD ENGINE ARRAY)就是 GPU 内核。之后,AMD 公司还联合各大厂商定义了异构系统体系结构(Heterogeneous System Architecture,HSA),包括平台定义[11]、程序参考手册[12]和动态运行环境定义[13],实现了 CPU 和 GPU 访存地址空间的统一化,为集成 CPU / GPU 处理器生态系统(包括硬件、编程技术以及上下游产品开发)奠定了基础。

GPU通用计算的发展历程
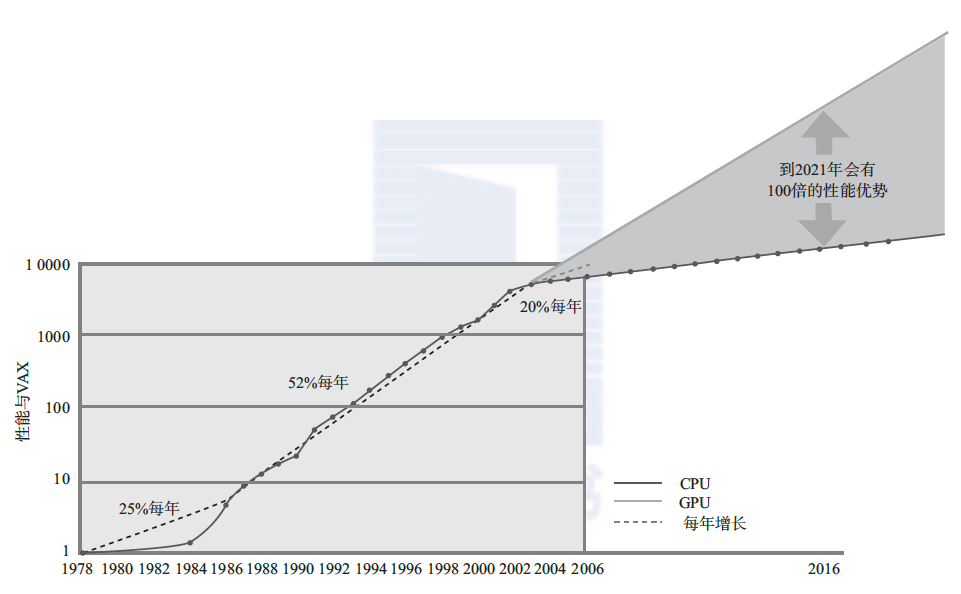
21 世纪的最初 5 年是 GPU 硬件发展的分水岭。一方面,CPU 经历了平均每年性能提升50% 以上的 20 年高速发展,逐渐进入性能饱和阶段,如图 1-18 所示。另一方面,GPU 由于可以充分利用图形显示过程的内在并行性,同时凭借图形应用的旺盛需求,性能却可以继续增加,终于在 2003 年全面超越 CPU。预计 GPU 将保持现有性能增长趋势直到 2020 年,届时单片 GPU 的性能将达到单片 CPU 的 100 倍左右。既然 GPU 表现出了这样出色的性能, 自 2004 年就有很多研究人员开始利用 GPU 进行耗时的科学计算。不过,当时人们还只能使用 OpenGL 或其他渲染语言编写通用计算程序,程序员需要将通用计算使用的数据结构翻译成图形结构(例如各种图元),因此开发调试困难较大。2006 年 CUDA 编程语言和工具的推出,虽然极大简化了 GPU 通用编程,但是只能使用 NVIDIA 公司的图形处理器。OpenCL 推出以后,真正的 GPU 通用编程时代来临了。
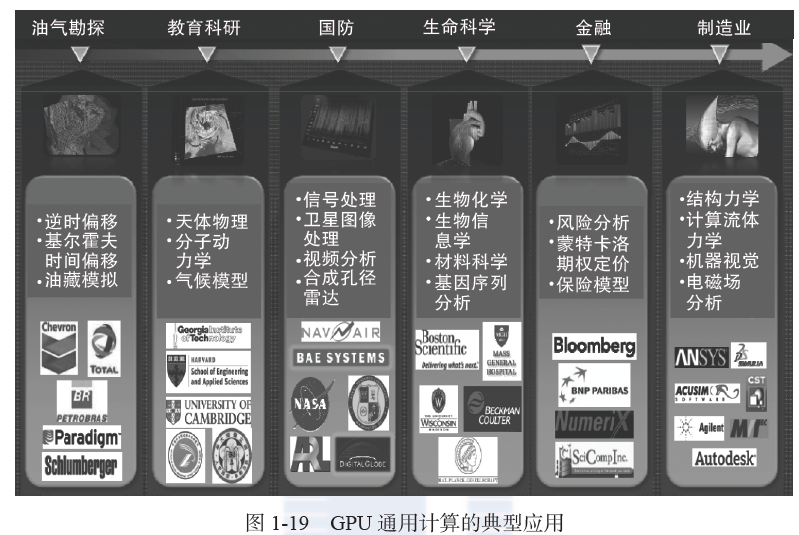
此后,GPU 通用计算被广泛应用于各种应用中,图 1-19 是对现有应用的不完全分类。其中,GPU 已经被用于油气勘探、军事、生命科学、金融、制造业等多种工业和科研领域,并为其中很多应用带来了革命性的突破。例如,此前分子动力学仿真需要 8 个月的时间才能计算百万数量级的原子在纳秒时间量级内的相互作用,随着 GPU 的引入,现在已经可以处理十亿数量级的原子。另一个例子是暴力密码破解,NVIDIA Fermi 级别的GPU 可以在 15 分钟左右破解 7 个字母的 MD5 密码,而 CPU 需要 4 天才能破解。随着大数据应用的蓬勃发展,GPU 通用计算的前景异常广阔。有兴趣的读者可以阅读参考文献[9]、[15]、[16],了解 GPU 通用计算的早期应用,参考文献[17]是对较新研究成果的综述。同时,由于 GPU 在单位功耗下提供的计算性能远高于 CPU,很多超级计算机也采用GPU 作为基本计算资源,如世界超级计算机前 10 名中有 5 个使用 NVIDIA Kepler GPU 和Intel Xeon Phi 众核处理器 ,绿色 500 超级计算机的前 10 名中有 9 个使用 GPU。
从峰值计算能力而言,GPU 相对 CPU 的优势是明显的,图形程序一般能够比较充分地发挥 GPU 的计算潜力。然而,并不是所有的通用程序都能完全利用计算平台的处理能力,除了部分稠密矩阵运算能够达到峰值运算能力的 80% 以外[19],大部分程序的利用率受限于其内部控制结构和内存访问模式等因素。那么,在通用计算应用中,GPU 的表现如何呢?参考文献 [20] 对现有应用进行了归纳总结,图 1-20 是相应的结果。首先,GPU 擅长执行计算密度比较高的程序,即每一字节需要浮点或整数运算较多的代码。图 1-20 的横轴是FLOP/Byte,即每字节数据的浮点运算。所以,横轴越靠右位置的程序计算密度越高,属于计算受限型应用,即影响性能的主要因素是计算资源不足;横轴越靠左位置的程序计算密度越低,属于存储受限型应用,即影响性能的主要因素是存储器带宽不足。对于计算受限型应用,GPU 执行性能一般比同代 CPU 高 10 ~ 20 倍,而对于存储受限型应用,一般加速比为5 ~ 10 倍。必须说明的是,图 1-20 中用到的程序仍然是比较适合 GPU 实现的程序。对于控制流程和访存模式复杂以及并行性不足的代码,GPU 的性能甚至可能低于 CPU。因此,CPU 和 GPU 更多的是互补关系,而不是互相取代的关系,这也是 AMD 在单片芯片上集成 CPU 和 GPU 的出发点。
Intel Xeon Phi 是作为 GPU 设计的,当时代号为 Larrabee[18],不过后来定位为专用计算加速器。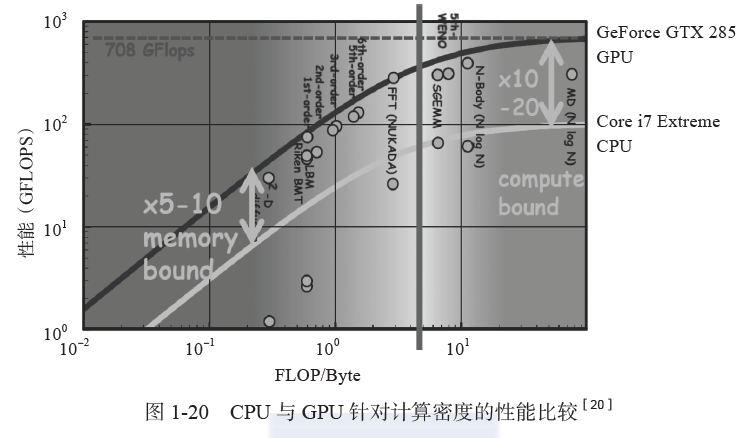
参考文献
[ 1 ] C O’Hanlon. A Conversation with John Hennessy and David Patterson [J]. ACM Queue, 2006-2007, 4(10): 14-22.
[ 2 ] T Theoharis, G Papaioannou, N Platis, et al. Graphics & Visualization Principles & Algorithms [M]. A. K. Peters, Ltd., 2008.
[ 3 ] Khronos. OpenGL Shading Language 4.40 Specification [S]. 2013.
[ 4 ] K A Duke, W A Wall. A Professional Graphics Controller [J]. IBM Systems Journal, 1985, 24(1): 14-25.
[ 5 ] J H Clark. The Geometry Engine: A VLSI Geometry System for Graphics [C]. Computer Graphics and Interactive Techniques, 1982, 127-133.
[ 6 ] H Fuchs, J Goldfeather, J P Hultquist, et al. Fast Spheres, Shadows, Textures, Transparencies, and Image Enhancements in Pixel-Planes [C]. Advances in Computer Graphics, 1985, 111-120.
[ 7 ] K Akeley. Reality Engine Graphics [C]. SIGGRAPH, 1993, 109-116.
[ 8 ] J Montrym, H Moreton. The GeForce 6800 [J]. IEEE Micro, 2005, 25(2): 41-51.
[ 9 ] J D Owens, D Luebke, N Govindaraju, et al. A Survey of General-Purpose Computation on Graphics Hardware [J]. Computer Graphics Forum, 2007, 26(1):80–113.
[10] J Nickolls, W Dally. The GPU Computing Era [J]. IEEE Micro, 2010, 30(2): 56-69.
[11] HSA Foundation. HSA Platform System Architecture Specification 1.0 [EB/OL]. 2014. http://www.hsafoundation.com/?ddownload=4944.
[12] HSA Foundation. HSA Programmer Reference Manual Specification 1.0 [EB/OL]. 2014.
 wechat
wechat alipay
alipay